

In times of Covid-19 the interest in remote access solutions has grown. Remote access has always been a hot topic for industrial control systems, some asset owners didn’t want any remote access, others made use of their corporate VPN solutions to create access to the control network, and some made use of the remote access facilities provided by their service providers. In this blog I will discuss a set of security controls to consider when implementing remote access.
There are multiple forms of remote access:
- Remote access from an external organization, for example a service provider. This requires interactive access, often with privileged access to critical ICS functions;
- Remote access from an internal organization, for example process engineers, maintenance engineers and IT personnel. Also often requires privileged access;
- Remote operations, this provides the capability to operate the production process from a remote location. Contrary to remote access for support this type of connection requires 24×7 availability and should not hinder the process operator to carry out his / her task;
- Remote monitoring, for example health monitoring of turbines and generators, well head monitoring and similar diagnostic and monitoring functions;
- Remote monitoring of the technical infrastructure for example for network performance, or remote connectivity to a security operation center (SOC);
- Remote updates, for example daily updates for the anti-virus signatures, updates for the IPS vaccine, or distribution of security patches.
The rules I discuss in this blog are for remote interactive access for engineering and support tasks, a guy or girl accessing the control system from a remote location for doing some work.
In this discussion I consider a remote connection to be a connection with a network with a different level of “trust”. I put “trust” between quotes because I don’t want to enter in all kind of formal discussions on what trust is in security, perhaps even if we should allow trust in our life as security professional.
RULE 1 – (Cascading risk) Enforce disjoint protocols when passing a DMZ.

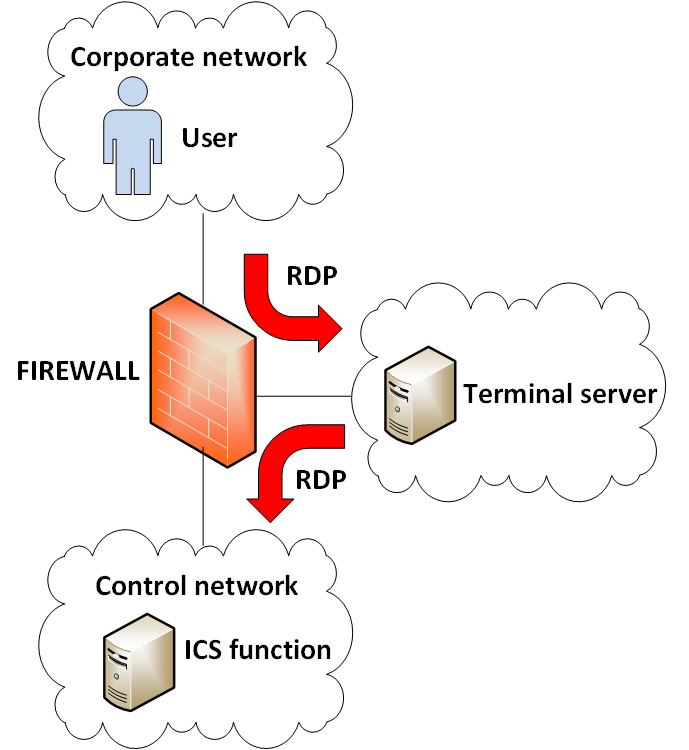
The diagram shows a very common architecture, but unfortunately also one with very high risk because of allowing inbound access into the DMZ toward the terminal server and allowing outbound access from the terminal server to the ICS function using the same protocol.
Recently we have had several RDP vulnerabilities that were “wormable”, meaning a network worm can make use of the vulnerability to propagate through the network. So allowing a network worm that infects the corporate network to reach the terminal server and from there infect the control network. Which is high risk in times of ransomware spreading as a network worm.
This is a very bad practice and should be avoided! Not enforcing disjoint protocols increases what is called cascading risk, the risk that a security breach propagates through the network.
RULE 2 – (Risk of hacking) Prevent inbound connections. Architectures where the request is initiated from the “not-trusted” side, like in above terminal server example, require an inbound firewall port to be open to facilitate the traffic. For example in above diagram the TCP port for the RDP protocol.
Solutions using a polling mechanism, where a function on the trusted side polls a function on the not-trusted side for access requests, offers a smaller attack surface because the response channel makes use of the firewall’s stateful behavior, where the port is only temporarily open for just this specific session.
Inbound connections expose the service that is used, if there would be a vulnerability in this service this might be exploited to gain access. Prevent at all times such connections coming from the Internet. Direct Internet connectivity requires a very good protection, an inbound connection for remote access offers a high risk for compromise.
So also a very bad practice, unfortunately a practice I came across to several times because some vendor support organizations use such connectivity.
RULE 3 – (Risk of exposed login credentials) Enforce two-factor authentication. The risk that the access credentials are revealed through phishing attacks capturing the access credentials is relatively big. Two factor authentication adds to this the requirements that apart from knowing the credentials (login / password) the threat actor also needs to possess access to a physical token generator for login.
This raises the bar for a threat actor. Personally I have the most trust in a physical token like a key fob that generates a code. Alternatives are tokens installed in the PC, either as software or as a USB device.
RULE 4 – (Risk of unauthorized access) Enforce an explicit approval mechanism where someone on the trusted side of the connection explicitly needs to “enable” remote access. Typically after a request over the phone either the process operator / supervisor or a maintenance engineer needs to approve access before the connectivity can be established.
Multiple solutions exist, some solutions have this feature build-in, sometimes an Ethernet switch is used, and there are even firewalls where a digital input signal can alter the access rule.
Sometimes implicit approval seems difficult to prevent, for example access to sub-sea installations, access to installations in remote areas, or access to unmanned installations. But also for these situations implementing explicit approval is often possible with some clever engineering.
RULE 5 – (Risk of prohibited traffic) Don’t allow for end to end tunneled connections between a server in the control network and a server at the not trusted side (either corporate network or a service provider network)
Encrypted tunnels prevent the firewall to inspect the traffic, so bypass more detailed checks on the traffic. So best practice is to break the tunnel have it inspected by the firewall and reestablish the tunnel to the node on the trusted side of the network. Where to break the tunnel is often a discussion, my preference is to break it in the DMZ. Tunneled traffic might contain clear text communication, so we need to be careful where to expose this traffic if we open the tunnel.
RULE 6 – (Risk of unauthorized activity) Enforce for connectivity with external users, such as service providers, a supervision function where someone on the trusted side can see what the remote user does and intervene when required.
Systems exist that no only supervise the activity visual, but also log all activity allowing it to be replayed later in time.
RULE 7 – (Risk of unauthorized activity) Make certain there is an easy method to disconnect the connection. A “supervisor” on the trusted side (inside) of the connection must be able to disconnect the remote user. But prevent that this can be done accidentally, because if the remote user does some critical activity, his control over the activity shouldn’t be suddenly lost.
RULE 8 – (Risk of unauthorized activity) Restrict remote access to automation system nodes as much as possible. Remote access to a safety engineering function might not be a good idea, so prevent this where possible. Where in my view this should be prevented with a technical control, an administrative policy is fine but generally not considered by an attacker.
RULE 9 – (Risk of unauthorized access) Restrict remote access for a limited time. A remote access session should be granted for a controlled length of time. The time duration of the session needs to match the time requirement of the task, never the less there should be an explicit end time that is reasonable.
RULE 10 – (Risk of exposure confidential data) Enforce the use of secure protocols for remote access, login credentials should not pass the network in clear text at any time. So for example don’t use protocols such as Telnet for accessing network devices, use the SSH protocol that encrypts the traffic instead.
In principle all traffic that passes networks outside the trusted zones should be encrypted and end to end authenticated. Using certificates is a good option, but it better be a certificate specifically for your plant and not a globally used certificate.
In times of state sponsored attackers, the opponent might have the same remote access solution installed and inspected in detail.
RULE 11 – (Risk of exposure confidential data) Don’t reveal login credentials of automation system functions to external personnel from service providers. Employees of service providers generally have to support tens or hundreds of installations. They can’t memorize all these different access credentials, so quickly mechanism are used to store these. Varying from paper to Excel spreadsheets and password managers, prevent that a compromise of this information compromises your system. Be aware that changing passwords of services is not always an easy task, so control this cyber security hazard.
A better approach might be to manage the access credentials for power users, including external personnel, using password managers that support login as a proxy function. In these systems the user only needs to know his personnel login credentials and the proxy function will use the actual credentials in the background. This has several security advantages:
- Site specific access credentials are not revealed, if access is no longer required, disabling / removing access to the proxy function is sufficient to block access without ever having compromised the system’s access credentials.
- Enforcing access through such a proxy function blocks the possibility of hopping between servers, because the user is not aware of the actual password. (This does require to enforce certain access restrictions for users in general.)
Also consider separating the management of login credentials for external users from the management of login credentials for internal users (users with a login on the trusted side). You might want to differentiate between what a user is allowed to do remotely and what he can do when on site. Best to enforce this with technical controls.
RULE 12 – (Risk of unauthorized activity) Enforce least privilege for remote activities. Where possible only provide view-only capabilities. This often requires a collaborative session where a remote engineer guides a local engineer to execute the actions, however it reduces the possibilities for an unauthorized connection to be used for malicious activity.
RULE 13 – (Risk of unauthorized activity) Manage access into the control network from the secure side, the trusted side. Managing access control and authorizations from the outside of the network is like putting your door key outside under the doormat. Even if the task is done from remote, the management systems should be on the inside.
RULE 14 – (Risk of unauthorized activity) Detection. Efi Kaufman addressed in a response a very valid point.
We need to build our situational awareness. The whole idea of creating a DMZ zone is to have one zone where we can do some detailed checks before we let the traffic in. In RULE 5, I already mentioned to break the tunnel open so we can inspect, but there is of course lots more to inspect. If we don’t apply detection mechanisms we have an exclusive focus on prevention assuming everyone behaves fine when we open the door.
This is unfortunately not true, so a detection mechanism is required to check if nothing suspicious happens. Exclusively focusing on prevention is a common trap, and I fell in it!
Robin, a former pen tester pointed out that it is important to monitor the antivirus function, as pentester he was able to compromise a system, because av triggering on the payload was not monitored, giving him all the time to investigate and modify the payload until it worked.
RULE 15 – (Risk of hacking, cascading risk) Patching, patching, patching. There is little excuse not to patch remote access systems, or systems in the DMZ in general. Exposure demands that we patch.
Beware that these systems can have connectivity with the critical systems, their users might be logged in using powerful privileges, privileges that could be misused by the attacker. Therefore patching is also very important.
RULE 16 – (Risk of malware infection, cascading risk) Keep your AV up to date. While we start to do some security operation tasks, better to make sure our AV signatures are up to date.
RULE 17 – (Risk unauthorized activities) Robin addressed in a response the need for enforcing that the remote user logs for each request the purpose of the remote access request. This facilitates identification if processes are followed, and people are not abusing privileges or logging in daily for 8 hours/day for a month instead of coming to site.
Seventeen simple rules to consider when implementing remote access that popped up in my mind while typing this blog.
If I missed important controls please let me know than I will add them.
Use these rules when considering how to establish remote connectivity for support type of tasks. Risk appetite differs, so engineers might only want to select some rules and accept a bit higher risk.
But Covid-19 should not lead to an increased risk of cyber incidents by implementing solutions that increase exposure on the automation systems in an irresponsible manner.
There is no relationship between my opinions and publications in this blog and the views of my employer in whatever capacity.
Author: Sinclair Koelemij