Are there rules an engineer must follow when executing a new project? This week Yacov Haimes passed away at the age of 86 years. Haimes was an American of Iraqi decent and a monument when it comes to risk modeling of what he called systems of systems. His many publications among which his books “Modeling and Managing Interdependent Complex Systems of Systems” (2019) and “Risk Modeling, Assessment, And Management” (2016) provided me with a lot of valuable insights that assisted me to execute and improve quantitative risk assessments in the process industry. He was a man who tried to analyze and formalize the subjects he taught and as such created some “models” that helped me to better understand what I was doing and guide me along the way.
Readers that followed my prior blogs know that I consider automation systems as Systems of Systems (SoS) and have discussed these systems and their interdependencies and interconnectedness (I-I) often in the context of OT security risk. In this blog I like to discuss some of these principles and point to some of the gaps I noticed in methods and standards used for risk assessments conflicting with these principles. To start the topic I introduce a model that is a merger between two methods, on one side the famous 7 habits of Covey and on the other side a system’s development process, and use this model as a reference for the gaps I see. Haimes and Schneiter published this model in a 1996 IEEE publication, I kind of recreated the model in Visio so we can use it as a reference.
A holistic view on system’s engineering Haimes and Schneiter (C) 1996 IEEE
I just pick a few points per habit where I see gaps between the present practice advised by standards of risk engineering / assessment and some practical hurdles. But I like to encourage the reader to study the model in far more detail than I cover in this short blog.
The first Stephen Covey habit is, habit number 1 “Be proactive” and points to the engineering steps that assist us in defining the risk domain boundaries and help us to understand the risk domain itself. When we start a risk analysis we need to understand what we call the “System under Consideration”, the steps linked to habit 1 describe this process. Let’s compare this for four different methods and discuss how these methods implement these steps, I show them above each other in the diagram so the results remain readable.
Four risk methods
The ISO 31000 is a very generic model, that can be used both for quantitative risk assessment as well as qualitative risk assessment. (See for the definitions of risk assessments my previous blog) The NORSOK model is a quantitative risk model used for showing compliance with quantitative risk criteria for human safety and the environment. The IEC/ISA 62443.3.2 model is a generic or potentially a qualitative risk model specifically constructed for cyber security risk as used by the IEC/ISA 62443 standard in general. The CCPS model is a quantitative model for quantitative process safety analysis. It is the 3rd step in a refinement process starting with HAZOP, then LOPA, and if more detail is required than CPQRA.
Where do these four differ if we look at the first two habits of Covey? The proactive part is covered by all methods, though CCPS indicates a focus on scenarios, this is primarily so because the HAZOP covers the identification part in great detail. Never the less for assessing risk we need scenarios.
An important difference between the models rises from habit 2 “Begin with the end”. When we engineer something we need clear criteria, what is the overall objective and when is the result of our efforts (in the case of a risk assessment and risk reduction, the risk) acceptable?
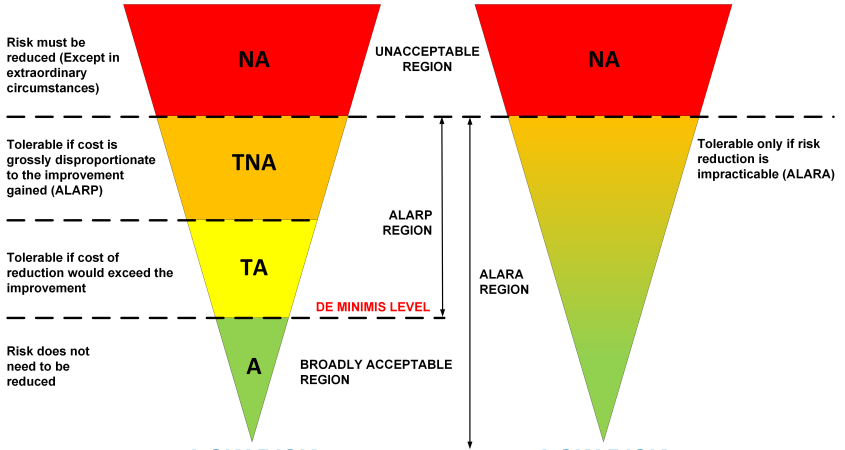
This is the first complexity and strangely enough are these criteria a hot topic between continents, my little question “when is risk acceptable?” is for many Americans an unacceptable question, the issue is their legal system which mixes “acceptability” and “accountability” so they translate this into “when is risk tolerable”. However the problem here is that there are multiple levels for tolerable. European law is as usual diverse, we have countries that follow the ALARP principle (As Low As Reasonably Practical) and we have countries that follow the ALARA principle (As Low As Reasonably Achievable). ALARP has a defined “DE MINIMIS” level, kind of a minimum level where we can say risk is reduced to a level that is considered an acceptable risk reduction by a court of law. Contrary to ALARA where we need to reduce the risk to the level it is no longer practicable, so there is no cost criterium but only a pure technical criterium.
ALARP, ALARA comparison
For example the IEC/ISA 62443-3-2 standard compares risk with the tolerable level without defining what that level is. For an ALARA country (e.g. Germany, Netherlands) that level is clearly defined by the law and the IEC / ISA interpretation (stopping further risk reduction at this level) would not be acceptable, for an ALARP country (e.g. UK) the limits and conditions are also well defined but cost related. The risk reduction must go all the way to the DE MINIMUS level if cost would allow it. Which is in cyber security for a chemical plant often the case, this because the cost of a cyber incident – that can cause one or multiple fatalities – in the UK this cost is generally higher than the cost of the cyber security measures that could have prevented it. The cost of a UK fatality is set to approx. 1.5 million pound, actually an American is triple that cost 😊according to the US legal system, the Dutch and Germans (being ALARA) are of course priceless.
So it is important to have clear risk acceptance criteria established and objectives when we start a risk assessment. If we don’t – such as is the case for IEC/ISA 62443.3.2 comparing initial and residual risk with some vaguely defined tolerable risk level – the risk reduction most likely fails a legal test in a court room. ALARP / ALARA are also legal definitions, and cyber security also needs to meet these. Therefore the step risk planning is an essential element of the first NORSOK step and in my opinion should always be the first step, engineering requires a plan towards a goal.
Another very important element according Haines is the I-I (interdependencies, interconnectedness) element. Interconnectedness is covered by IEC/ISA 624433.2 by the zone and conduit diagram, conduits connect zones, though these conduits are not necessarily documented at the level allowing us to identify connections within the zone that can be of relevance for cyber risk (consider e.g. ease of malware propagation within a zone).
Interdependencies are ignored by IEC/ISA 62443. The way to identify these interdependencies is typically conducting a criticality analysis or a Failure Mode and Effect Analysis (FMEA). Interdependencies propagate risk because the consequence of function B might depend on the contribution of function A. A very common interdependency in OT is when we take credit in a safety risk analysis for both a safeguard provided by the SIS (e.g. a SIF) and a safeguard provided by the BPCS (e.g. an alarm), if we need to reduce risk with a factor 10.000, there might be a SIL 3 SIF defined (factor 1000) and the BPCS alarm (factor 10). If a cyber attack can disable one of the two the overall risk reduction fails. Disabling process alarms is relatively easy to do with a bit of ARP poisoning, so from a cyber security point of view we have an important interdependency to consider.
Habit 1 and 2 are very important engineering habits, if we follow the prescriptions taught by Haines we certainly shouldn’t ignore the dependencies when we analyze risk as some methods do today. How about habit 3? This habit is designed to help concentrate efforts toward more important activities, how can I link this to risk assessment?
Especially when we do a quantitative risk assessment vulnerabilities aren’t that important, threats have an event frequency and vulnerabilities are merely the enablers. If we consider risk as a method that wants to look into the future, it is not so important what vulnerability we have today. Vulnerabilities come and go, but the threat is the constant factor. The TTP is as such more important than the vulnerability exploited.
Of course we want to know something about the type of vulnerability, because we need to understand how the vulnerability is exposed in order to model it, but if we yes/no have a log4j vulnerability is not so relevant for the risk. Today’s log4j is tomorrow’s log10k. But it is essential to have an extensive inventory of all the potential threats (TTPs) and how often these TTPs have been used. This information is far more accessible than how often a specific exposed (so exploitable) vulnerability exists. We need to build scenarios and analyze the risk per scenario.
Habit 4 is also of key importance, win-win makes people work together to achieve a common goal. The security consultant’s task might be to find the residual risk for a specific system, but the asset owner typically wants more than a result because risk requires monitoring, risk requires periodic reassessment. The engineering method should support these objectives in order to facilitate the risk management process. Engineering should always consider the various trade-offs there are for the asset owner, budgets are limited.
Habit 5 “Seek first to understand, then to be understood” can be directly linked to the risk communication method and linked to the perspective of the asset owner on risk. So reports shouldn’t be thrown over the wall but discussed and explained, results should be linked to the business. Though this might take considerably more time it is never the less very important.
But not an easy habit to acquire as engineer since we often are kind of nerds with an exclusive focus on “our thing” expecting the world to understand what is clear for us. One of the elements that is very important to share with the asset owner are the various scenarios analyzed. The scenario overview provides a good insight in what threats have been evaluated (typically close to 1000 today, so a sizeable document of bow-ties describing the attack scenarios and their consequences) and the overview allows us to identify gaps between the scenarios assessed and the changing threat landscape.
Habit 6 “Synergize”, is to consider all elements of the risk domain but also their interactions and dependencies. There might be influences from outside the risk domain not considered, never the less these need to be identified another reason why dependencies are very important. Risk propagates in many ways, not necessarily exclusively over a network cable.
Habit 7 “Sharpen the saw”, if there is one discipline where this is important than it is cyber risk. The threat landscape is in continuous movement. New attacks occur, new TTP is developed, and proof of concepts published. Also whenever we model a system, we need to maintain that model, improve it, continuously test it and adjust where needed. Threat analysis / modelling is a continuous process, results need to be challenged, new functions added.
Business managers typically like to develop something and than repeat it as often as possible, however an engineering process is a route where we need to keep an open eye for improvements. Habit 7 warns us against the auto-pilot. Risk analysis without following habit 7 results in a routine that doesn’t deliver appropriate results, one reason why risk analysis is a separate discipline not just following a procedure as it still is for some companies.
There is no relationship between my opinions and references to publications in this blog and the views of my employer in whatever capacity. This blog is written based on my personal opinion and knowledge build up over 43 years of work in this industry. Approximately half of the time working in engineering these automation systems, and half of the time implementing their networks and securing them, and conducting cyber security risk assessments for process installations since 2012.
Approximately 30 years ago J. Bond (Not James but John – “The Hazards of Life and All That”) introduced the three laws of loss prevention:
He who ignores the past is condemned to repeat it.
Success in preventing a loss is in anticipating the future.
You are not in control if a loss has to occur before you measure it.
The message for cyber security seems to be that when we measure and quantify the degree of resilience that OT security provides or an installation requires, we learn something from that. When we measure, we can compare / benchmark, predict and encapsulate the lessons learned in the past in a model looking into the future. One way of doing this is by applying quantitative risk methods.
Assessing risk is done using various methods:
We can use a qualitative method which will produce either a risk priority number or a value on an ordinal scale (high, low, ..) for the scenario (if scenarios are used, we discuss this later) for which the risk is estimated. The qualitative method is very common because it is easy to do, but often also results in a very subjective risk level. Never the less I know some large asset owners used such a method to assess cyber security risk for their refinery or chemical plant. Care must be taken that qualitative risk assessments don’t result in a form generic risk assessment, becoming more a risk awareness exercise than providing risk in terms of likelihood and consequence as a base for decision making.
Another approach is to use a quantitative method, which will produce a quantitative threat event frequency, or probability value for an attack scenario analyzed and considers how risk reduction controls reduce the risk. Quantitative methods require more effort and are traditionally only used in critical situations, for example in cases where an incident can result in fatalities. This because regulatory authorities specify quantitative limits for both worker risk and societal risk for production processes. Today we have also computational methods developed that reduce the effort of risk estimation significantly. An advantage of a quantitative method is that a quantitative result expresses risk in terms of likelihood (event frequency or probability) and consequence and links these to the risk reduction the security measures offer. Providing a method of justification.
A Generic risk assessment is an informal risk assessment, e.g. an asset owner and my employer wants me to consider the risk whenever I apply changes to an OT function. Generic risk is a high level process, considering what are the potential impacts of the modification, where can things go wrong, how do I recover if it goes wrong, who needs to be aware of the change and the potential impact? Most of us are very familiar with this way of accessing risk, for example when we cross a busy street we do this immediately. Also generic risk assessments are used by the industry, but they are informal and depend very much on the skills and experience of the assessor.
Dynamic risk assessment is typically used in situations where risk continuously develops such as is the case for firemen during a rescue operation, or a security operations center might apply this method while handling a cyber attack trying to contain the attack.
If we need to estimate risk for loss events during the conceptual or design phase of an industrial facility, we estimate risk for potential consequences for human health, environment, and finance. In those cases a quantitative method is important because it justifies the selected (or ignored) security measures. A quantitative risk assessment for loss events is an extension of the plant’s process safety risk analysis, typically a process safety HAZOP normally followed by a LOPA.
In oil and gas, refining and the chemical industry it is quite normal that the HAZOP identifies hazards that can result in fatalities or significant financial loss. Just like there are loss scenarios identified that result in serious environmental impact. For hazards concerning human safety and environmental loss the governments have set limits, limits that set a limit on how often such an event may occur per annum.
These limits are used by process safety engineers for setting their design targets for each consequence rating (Target Mitigated Event Likelihood – TMEL) on which they base the selection of the safeguards that reduce the risk in order to meet the required TMEL. Such a risk estimation process is typically carried out in the Layers Of Protection Analysis (LOPA). LOPA is a high level risk estimation process that typically follows a HAZOP. The HAZOP follows a systematical method to identify all potential safety hazards with their causes and consequences. The LOPA is the step following a HAZOP analysis performing a high level risk analysis for estimating a mitigated event likelihood frequency of the most critical hazards, for example the hazards with a high consequence rating.
LOPA is a semi-quantitative method using a set of predefined event frequencies for specific accidents (e.g. pump failure, leaking seal, ..) and predefined values for the risk reduction that safeguards offer when mitigating such an event. For example a safety instrumented function with SIL 2 safety integrity level offers a risk reduction of factor 100, a SIL 3 safeguard would offer a factor 1000, and a process operator intervention a factor 10. The SIL values are a function of the reliability and test frequency of the safeguard. Based upon these factors a mitigated event likelihood is estimated, and this likelihood must meet the TMEL value. If this is not the case additional or alternative safeguards (controls) are added to meet the TMEL value. Loss events for industrial installations are assigned a consequence rating level, and for each rating level a TMEL has been defined. For example the highest consequence rating might have a TMEL of 1E-05 assigned, the one but highest 1E-04, etc.
For the law the cause of a consequence like a fatality or environmental spill is irrelevant, the production process must offer a likelihood level that meets the legal criteria whatever the cause. For example we might need to meet a TMEL of 1E-06 for a consequence involving multiple fatalities for a greenfield installation in Europe, or a maximum TMEL of 1E-05 for existing brown field installations. This means that if a cyber attack can cause a fatality / irreversible injury, or major environmental damage, the likelihood of such an event (so its event frequency) must meet the same TMEL as is valid for the safety accident. The law doesn’t give bonus points for the one (safety) being accidental, and the other (cyber security) being intentional. Risk must be reduced to the level specified. To estimate such an event likelihood frequency as result of a cyber attack requires a quantitative process. So far the introduction.
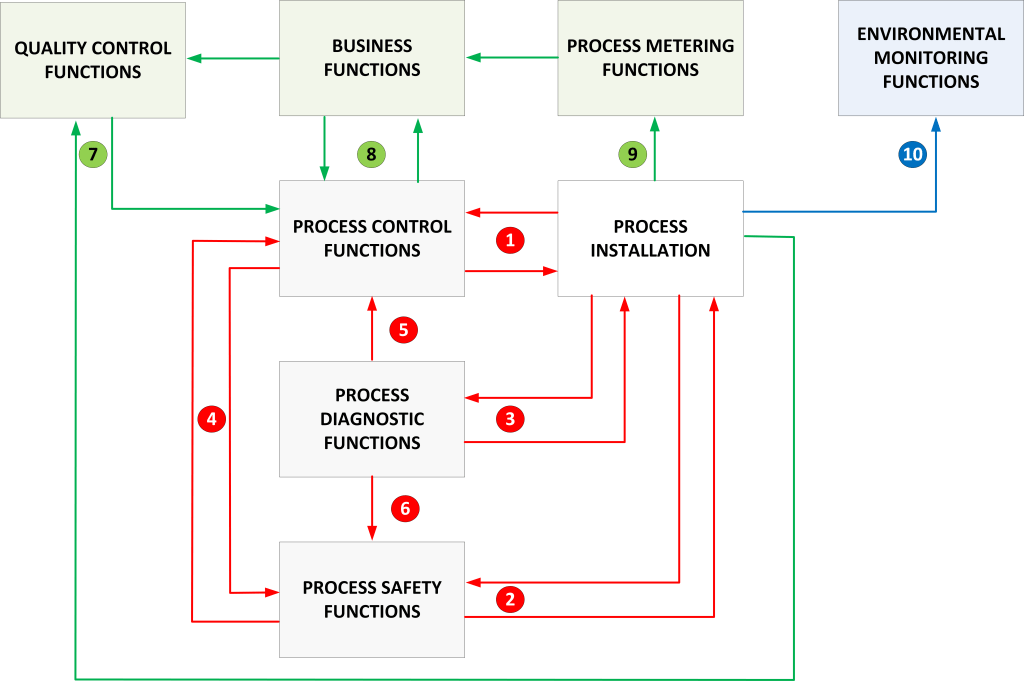
Let’s first look at loss events and how they can arise in a production facility like a chemical plant. For this I created the following overview picture for showing the relevant automation function blocks in a production process. It is a high level overview ignoring some shared critical support components such as a HVAC that can also cause loss events if it would fail, or various management systems (network, security, documentation, ..) that can be misused to get access to the OT functions. I also ignore the network segmentations for now, network segmentation is managing the exposure of the functions so important for estimating the likelihood but not for this loss event discussion.
Overview of the automation functions
I start my explanation with discussing the blocks in the diagram.
Process Control Functions – These are the collection of functions that control the production process, such as the basic process control system function (BPCS), the compressor control function (CCS), power management function (PMS), Advanced Process Control functions (APC), Motor Control Center function (MCC), Alarm Management function (ALMS), Instrument Asset Management function (IAMS), and several other functions depending on the type of plant. All specialized systems that execute a specific task in the control of a production process.
Process Safety Functions – Examples of process safety functions are the Emergency Shutdown function (ESD), burner management function (BMS), fire and gas detection function (F&G), fire alarm panel function (FAP), and others. Where the control functions execute the production process, the safety function guards that the production process stays within safe process limits and intervenes with a partial or full shutdown if this is not the case.
Process diagnostic functions – Examples of process diagnostic functions are machine monitoring systems (MMS) (e.g. vibration monitoring), and process analyzers (PA) (e.g. oxygen level monitoring). These functions can feed the process safety function with information that initiates a shutdown. For example the oxygen concentration in a liquid is measured by a process analyzer, if this concentration is too high an explosion might occur if not prevented by the safety function. Process analyzers are typically clustered in management systems that control their calibration and settings. These functions are network connected, similar as is the case for analyzers also HART, Profibus, or Foundation Fieldbus are network connected and can be attacked.
Quality control functions – For example a Laboratory Information Management System (LIMS) keeps track of the lab results, is responsible for the sample management, instrument status, and several other tasks. Traditionally LIMS was a function that was isolated from the process automation functions, but nowadays there are also solutions that feed their data directly into the advanced process control (APC) function.
Process metering functions – These are critical for custody transfer applications, monitoring of production rates, and in oil and gas installations monitor also well depletion. For liquids the function is a combination of a pump and precision metering equipment, however there are also power and gas metering systems.
Environmental monitoring systems – These systems monitor for example the emission at a stack or discharges to surface water and groundwater. Failure can result in regulatory violations.
Business functions – This is a large group of functions ranging from systems that estimate energy and material balances to enterprise resource planning (ERP) systems, tank management functions, and jetty operation and mooring load monitoring are considered in this category. This block contains a mixture of OT related functions and pure information technology systems (e.g. ERP), exchanging information with the automation functions. Business function is not the same as an IEC 62443 level 4 function, it is just a group of functions directly related with the production process and potentially causing a loss event when a cyber attack occurs. They have a more logistic and administrative function, but depending on the architecture can reside at level 3, level 4 or level 5.
Process installation / process function – Least but not last the installation that creates the product. The pumps, generators, compressors, pipes, vessels, reactors, etc. For this discussion I consider valves and transmitters for a risk perspective to be elements of the control and safety functions.
The diagram shows numbered lines representing data and command flows between the function blocks. That doesn’t mean that this is the only critical data exchange that takes place, also within the blocks there are critical interactions between functions and their components that a risk assessment must consider. Such as for example the interaction between BPCS and APC, BPCS and CCS, BPCS and PMS, ESD and F&G. But also data exchange between the components of the main function, for example the information flow between an operator station and a controller in a BPCS, or the data flow between two safety controllers of a SIS. However that is at detailed level and mainly of importance when we analyze the technical attack scenarios. For determining the loss scenarios these details are of less relevance.
The diagram attempts to identify where we have direct loss (safety, environmental, financial) as result of the block functions failing to perform their task or performing their task in a way that does not meet the design and operational intentions of the function. Let’s look at the numbers and identify these losses:
This process control function information / command flow can cause losses in all three categories (Safety, environmental, finance). In principle a malfunction of the control system shouldn’t be able to cause a fatality, the safety function should intervene in time, never the less scenarios exist that are out of control of the process safety function where an attack on the BPCS can cause a loss with a high consequence rating. These cyber attack scenarios exist for all three categories, but of course this also depends on the type and criticality of the production process and the characteristics of the process installation.
Process safety functions have the task to intervene when process conditions are no longer under control by the process operator, however they can also be used to cause a loss event independent of the control function. A simple example would be to close a blocking valve (installed as a safety mechanism to isolate parts of the process) on the feed side of a pump, this would overheat and damage the pump if the pump wouldn’t be stopped. Also when we consider burner management for industrial furnaces multiple scenarios exist that can lead to serious damage or explosions if purge procedures would be manipulated. Therefore also the process safety function information/command flow can cause losses in all three categories (Safety, environmental, and finance).
Process diagnostic functions can cause loss events by not providing accurate values, for example incorrect analyzer readings or incorrect vibration information. In the case of rotating equipment a vibration monitoring function can also cause a false trip of for example a compressor or generator. Also this diagnostic function data and command flow can cause losses in all three categories (Safety, environmental, finance), specifically cyber attacks on the process analyzer through their management system can have serious consequences including explosions with potentially multiple fatalities. Analyzers are in my opinion very much under-estimated as potential target, but manipulated analyzer data can result in serious consequences.
The flow between the process control and process safety functions considers the exchange of information and commands between the control function and the process safety function. This would typically be alarm and status information from the process safety function and override commands coming from the process control function. Unauthorized override actions, or false override status information can lead to serious safety incidents. Just as loss SIL alarms can result in issues with the safety function not being noticed. In principle this flow can cause losses in all three categories (Safety, environmental, finance) though serious environmental damage is not likely.
The flow between the diagnostic and control functions might cause the control function to operate outside normal process conditions because of for example manipulating process analyzer data. In principle this can cause both environmental and financial damage, but most likely (Assuming the process safety function is fully operational) no safety issues. So far I have never came across a scenario for this flow that scores in the highest safety or environmental category, but multiple examples exist for the highest financial category.
The flow between the diagnostic and process safety functions is more critical than flow 5. This because flow 6 typically triggers the process safety function to intervene. If this information flow is manipulated or blocked, the process safety function might fail to act when demanded resulting in serious damage or explosions with losses in all three categories (Safety, environmental, finance).
This information flow between the quality control function, the process installation, and the process function is exclusively critical for financial loss events. The loss event can be caused by manipulated quality information leading to off spec product either being produced or sold to customers of the asset owner.
Manipulation of the information flow between the business functions and the control functions has primarily a financial impact. Though there are exceptions, for example there exist permit to work solutions (business function) that integrate with process operator status information. Manipulation of this data might potentially lead to safety accidents due to decisions based on incorrect status data.
Manipulation of the information flow between metering functions and the business functions results primarily in financial damage. It normally has neither a safety or environmental impact. However the financial damage can be significant.
The environmental monitoring function is an independent stand-alone function which loss is typically a financial loss event as result of not meeting environmental regulations. But minor environmental damage can be a consequence too.
Now we have looked at the loss events I like to change to the topic on how these loss events occur as result of a cyber attack on the automation functions. The diagram I created for this shows on the right side loss event categories, categories for process loss events and categories for business loss events. I don’t further discuss these in this blog, but these categories are used in the risk assessment reporting to group the risk of loss events allowing various comparison metrics showing differences between process installations. Primarily used for benchmarking, however this data gives an interesting view on the criticality of cyber attacks for different industries and the community.
Loss and threat relationship
The above graphic introduces which cyber security threats we analyze in a risk assessment and why. Threats are basically modelled as threat actors executing threat actions exploiting exposed vulnerabilities resulting in some unwanted consequence. We bundle threats in hazards, for example the hazard unauthorized access into a BPCS engineering HMI would be the grouping of all threats (attack scenarios) that can accomplish such unauthorized access. If the threat would succeed to accomplish this unauthorized access, a hazard would also have a series of consequences. These consequences are different depending on if we discuss the risk for the production process / installation or the risk for the business functions. Typically loss events for a process installation can be a safety, environmental, or financial loss event. While the impact on the business functions is typically financial loss.
Important to realize is that risk propagates, something that starts in the process installation can have serious impact for the business processes, but reverse is also true something that starts by a compromise of the business functions can lead to serious failures in the production installation. There for a risk assessment doesn’t separate IT and OT technology, it about functions and their mutual dependencies. This is why a criticality assessment (business impact) is an important instrument for identifying the risk domain for a risk analysis.
In a risk analysis we map the technical hazard consequences on the process and business loss scenarios. On the process / installation side there are basically two potential deviations: either the targeted function doesn’t perform anymore meeting design or operation intent; or the targeted function stops doing its task all together. These can result in process loss events. On the business side we have the traditional availability, confidentiality, and integrity impact. Data transfers can be lost, or their confidential content can get exposed, or the data can be manipulated all resulting in business loss events.
So the overall risk estimation process is identifying the scenarios (process and business), identify if they can be initiated by a cyber attack, if so then identify the functions that are the potential target and determine for these functions the cyber attack scenarios that lead to the desired functional deviations.
These attack scenarios are coming from a repository of attack scenarios for all the automation functions and their components in scope of the risk analysis. Doing this for multiple threat actors, multiple automation functions, and different solutions (having different architectures, using different protocols, having different dependencies between functions) for different vendors leads to a sizeable repository of cyber attacks with the potential security measures / barriers to counter these attacks.
In an automated risk assessment the technical architecture of the automation system is modelled in order to take the static and dynamic exposure of the targets (assets and protocols) into account, consider the exploitability of the targets, consider the intent, capabilities, and opportunity of the threat actors, and consider the risk reduction offered by the security measures. The result is what we call the threat event frequency, which is the same as what is called the mitigated event likelihood in the process safety context.
So far the attack scenarios considered are all single step attack scenarios against a targeted function. If the resulting mitigated event likelihood (MEL) meets the target mitigated event likelihood (TMEL) of the risk assessment criteria we are ready, the risk would meet the criteria. If not, we can add security measures to further reduce the mitigated event likelihood. In many cases this will reduce the MEL to the required level, if all functions are sufficiently resilient against a single step cyber attack than we can conclude the overall system is sufficiently resilient. However there are still cases where the TMEL is not met, even with all possible technical security measures implemented. In that case we need to extend the risk estimate by considering multi-step attack scenarios in the hope that this would reduce the overall probability of the cyber attack.
A multi-step attack scenario introduces significant challenges for a quantitative risk assessment. First we need to construct these multiple step attack scenarios, these can be learned from historical cyber attacks and otherwise using threat modelling techniques. Another complication is that in analyzing single step attack scenarios we used event frequencies, in multi-step attack scenarios this is no longer possible because we need to consider the conditional probability for the steps. The possibility of step B typically depends on the success of step A. So we need to convert the mitigated event frequencies of a specific single step into probabilities. This requires us to use a specific period, so calculate the probability for something like: “what is the probability that a threat with a mitigated event frequency of once every 10.000 years will occur in the coming 10 years”. Having a probability value we can add or multiply the probabilities in the estimation process. The chosen period for the probability conversion is not of much importance in this case because in the end we need to convert probability back into event frequency for comparison with the TMEL. Of more importance is if the conditional events are dependent or independent, this tells us to either multiply (independent) or add (dependent) probabilities which either increases or decreases likelihood.
For example if we have a process scenario that requires both to attack the control engineering function and the safety engineering function simultaneously, the result differs significantly if these functions require two independent cyber attacks or if a single cyber attack can accomplish both attack objectives. As would be the case if both engineering functions would reside in the same engineering station. This is why proper separation of the control and safety functions is also from a risk perspective very important. Mathematics and technical solutions go hand in hand.
So in a multi-step scenario we consider all steps of our attack scenario toward the ultimate target that creates the desired functional deviation impacting the production process. If these were all independent steps the conditional probability would have decreased compared with the single step estimate and as such also the likelihood if we convert the resulting conditional probability back into an event frequency (using the same period – e.g. the 10 years in my example). So far I never met a case where this wasn’t sufficient to be able to meet the TMEL. However it is essential to construct a multi-step scenario with the least amount of steps, otherwise we get an incorrect result because of too many steps between the threat actor and the target.
Never the less there is the theoretical possibility that in despite of considering all security measures available, in despite of considering the extra hurdles a multi-step attack poses, we still don’t meet the TMEL. In that case we have a few options:
One possibility is considering another risk strategy, so far we chose a risk mitigation strategy (trying to reduce risk using security measures). An alternative strategy can be a risk avoidance strategy, choosing for abandoning the concept all together or as alternative redesign the concept using another technical solution which potentially offers more or different options to mitigate the risk.
Risk strategies such as sharing risk (insurance) or spreading risk typically don’t work when it concerns non financial risk such as safety risk and environmental risk.
But as I mentioned so far I never encountered a situation where the TMEL could not be met with security measures, in the majority of the cases the compliance can be reached by analyzing single step scenarios for the targets. In some critical cases multi-step scenarios are required to estimate if risk reduction meets the criteria.
We might ask ourselves the question are we not overprotecting the assets if we attempt to solve mitigation by first establishing resilience against single step cyber attacks. This is certainly a consideration in the case where the insider attack can be ignored, but be aware that the privileged malicious insider typically can execute a single step attack scenario because of his / her presence within the system and having authorizations in the system. Offering sufficient protection against an insider attack most often requires procedures, non-technical means to control the risk. However so far there is no method developed that estimates the risk reduction of procedural controls for cyber security.
So what does a quantitative risk assessment offer? Well first of all a structural insight in a huge amount of attack scenarios, a growing amount of attack scenarios. It offers a way to justify investment in cyber security. It offers a method to show compliance with regulatory requirements for worker, societal, and environmental risk. And overall it offers consistency of the results and therefore a method for comparison.
What are the challenges, we need data for event frequencies. We need a method to estimate the risk reduction for a security measure. And we need knowledge, detailed knowledge on the infrastructure, the attack scenarios, process automation, a rare combination that only large and specialized service providers can offer.
The method does not provide actuarial risk, but it proofed in many projects to provide reliable and consistent risk. The data challenge is typically handled by decomposing the problem in smaller problems for which we can find reliable data. Experience and correction over time makes it time after time better. Actually in the same way as the semi quantitative LOPA method gained acceptance in the process safety world, the future for cyber risk analysis is in my opinion quantitative.
Strangely enough there are also many that disagree my statement, they consider (semi-)quantitative risk for cyber security as impossible. They often select as an alternative a qualitative or even a generic method, but both qualitative and generic methods are based on even less objective data. More subjective and not capable of proofing compliance to risk regulations. So the data argument is not very strong and has been concurred in many other risk disciplines. The complexity argument is correct, but that is time and education. Also LOPA was not immediately accepted, and LOPA as it is today is very structured and relatively simple to execute by subject matter experts. However we can also discuss data reliability for the LOPA method, comparing LOPA tables used by different asset owners also leads to surprises. Never the less LOPA has offered a tremendous value for a consistent and adequate process safety protection.
Process safety and cyber security differ very much but are also very similar. I believe cyber security must follow the lessons learned by process safety and adapt these for their own unique environment. This doesn’t happen very much resulting in weak standards such as for example the IEC 62443-3-2 ignoring what happens in the field.
There is no relationship between my opinions and references to publications in this blog and the views of my employer in whatever capacity. This blog is written based on my personal opinion and knowledge build up over 43 years of work in this industry. Approximately half of the time working in engineering these automation systems, and half of the time implementing their networks and securing them, and conducting cyber security risk assessments for process installations since 2012.
There is a revived attention for supply chain attacks after the seize of a Chinese transformer in the port of Houston. While on its way to a US power transmission company – Western Area Power Administration (WAPA) – the 226 ton transformer was rerouted to Sandia National Laboratories in Albuquerque New Mexico for inspection on possible malicious implants.
The sudden inspection happens more or less at the same time that the US government issued a presidential directive aiming for white listing vendors allowed to supply solutions for the US power grid, and excluding others to do so. So my curiosity is raised and additionally triggered by the Wall Street Journal claim that transformers do not contain software-based control systems and are passive devices. Is this really true in 2020? So the question is, are power transformers “hackable” or must we see the inspection exclusively as a step in increasing trade restrictions.
Before looking into potential cyber security hazards related to the transformer, let’s first look at some history of supply chain “attacks” relevant for industrial control systems (ICS). I focus here on supply chain attacks using hardware products because in the area of software products, Trojan horses are quite common.
Many supply chain attacks in the industry are based on having purchased counterfeit products. Frequently resulting in dangerous situations, but generally driven by economic motives and not so much by a malicious intent to damage the production installation. Some examples of counterfeits are:
Transmitters – We have seen counterfeit transmitters that didn’t qualify for the intrinsic safety transmitter zone qualifications specified by the genuine product sheet. And as such creating a dangerous potential for explosions in a plant when these products would be installed in zone 1 and zone 0 areas with a potential for the presence of explosive gases.
Valves – We have seen counterfeit valves, where mechanical specifications didn’t meet the spec sheet of the genuine product. This might lead to the rupture of the valve resulting in a loss of containment with potential dangerous consequences.
Network equipment – On the electronic front we have seen counterfeit Cisco network equipment that could be used to create a potential backdoor in the network.
However it seems that the “attack” here is more an exploit of the asset owner’s vulnerability for low prices (even if they sound ridiculously low), in combination with highly motivated companies trying to earn some fast money, than an intentional and targeted attack on the asset integrity of an installation.
That companies selling these products are often found in Asia, with China as the absolute leader according to reports, is probably caused by a different view / attitude toward patents, standards and intellectual property in a fast growing region and additionally China’s economic size. Not necessarily a plot against an arrogant Western world enemy.
The most spectacular example of such an incident is where counterfeit Cisco equipment ended up in the military networks of the US. But as far as I know, it was also in this case never shown that the equipment’s functionality was maliciously altered. Main problem was a higher failure rate caused by low manufacturing standards, potentially impacting the networks reliability. Never the less also here a security incident because of the potential for malicious functionality.
Also proven malicious incidents have occurred, for instance in China, where computer equipment was sold with already pre-installed malware. Malware not detectable by antivirus engines. So the option to attack industrial control systems through the supply chain certainly exist, but as far as I am aware never succeeded.
But there is always the potential that functionality is maliciously altered, so we need to see above incidents as security breaches and consider them to be a serious cyber security hazard we need to address. Additionally power transformers are quite different from the hardware discussed above, so a supply chain attack on US power grid using power transformers is a different analysis. If it would happen and was detected it would mean end of business for the supplier, so stakes are high and chances that it happens are low. Let’s look now at the case of the power transformer.
For many people, a transformer might not look like an intelligent device. But in today’s world everything in the OT world becomes smart (not excluding the possibility we ourselves might be the exception), so we also have smart power transformers today. Partially surfing on the waves of the smart hype, but also adding new functions that can be targeted.
Of course I have no information on the specifications of the WAPA transformer, but it is a new transformer so probably making use of today’s technology. Since seizing a transformer is not a small thing, transformers used in the power transmission world are designed to carry 345 kilo volts or more and can weigh as much as 410 tons (820.000 lb in the non-metric world), there must be a good reason to do so.
One of the reasons is of course that it is very critical and expensive equipment (can be $5.000.000+) and is built specifically for the asset owner. If it would fail and be damaged, replacement would take a long time. So this equipment must not only be secure, but also be very reliable. So worth an inspection from different viewpoints.
What would be the possibilities for an attacker to use such a huge lump of metal for executing a devious attack on a power grid. Is it really possible, are there scenarios to do so?
Since there are many different types of power transformers, I need to make a choice and decided to focus on what are called conservator transformers, these transformers have some special features and require some active control to operate. Looking at OT security from a risk perspective, I am more interested in if a feasible attack scenario exists – are there exposed vulnerabilities to attack, what would be the threat action – then in a specific technical vulnerability in the equipment or software that make it happen today. To get a picture of what a modern power transformer looks like, the following demo you can play with (demo).
Look for instance at the Settings tab and select the tap position table from where we can control or at minimum monitor the onload tap changes (OLTC). Tap changers select variable turn ratios to either increase or decrease the turn ratio to regulate the output voltage for variations on the input side. Another interesting selection you find when selecting the Home icon, leading you directly to the Buchholz safety relay. Also look at the interface protocol Goose, I would say it all looks very smart.
I hope everyone realizes from this little web demo, that what is frequently called a big lump of dumb metal might actually be very smart and containing a lot more than a view sensors to measure temperature and level as the Wall Street Journal suggests. Like I said I don’t know WAPA’s specification, so maybe they really ordered a big lump of dumb metal but typically when buying new equipment companies look ahead and adopt the new technologies available.
Let’s look in a bit more detail to the components of the conservator power transformer, being a safety function the Buchholz relay is always a good point to start if we want to break something. The relay is trying to prevent something bad from happening, what is this and how does this relay counter this, can we interfere?
A power transformer is filled with insulating oil to insulate and serve as a coolant between the windings. The Buchholz relay connects between the overhead conservator (a tank with insulating oil) and the main oil tank of the transformer body. If a transformer fails, or is overloaded this causes extra heat, heated insulating oil forms gas and the trapped gas presses the insulating oil level further down (driving it into the conservator tank passing the Buchholz relay function) so reducing the insulation between the windings. The lower level could cause an arc, speeding up the process and causing more gas pressure, pressing the insulating oil even more away and exposing the windings.
It is the Buchholz relay’s task to detect this and operate a circuit breaker to isolate the transformer before the fault causes additional damage. If the relay wouldn’t do its task quick enough the transformer windings might be damaged causing a long outage for repair. In principal Buchholz relays, as I know them, are mechanical devices working with float switches to initiate an alarm and the action. So I assume there is not much to tamper with from a cyber point of view.
How about the tap changer? This looks more promising, specifically an on load tap changer (OLTC). There are various interesting scenarios here, can we make step changes that impact the grid? When two or more power transformers work in parallel, can we create out-of-step situations between the different phases by causing differences in operation time?
An essential requirement for all methods of tap changing under load is that circuit continuity must be maintained throughout the tap stepping operation. So we need a make-before-break principle of operation, which causes at least momentary, that a connection is made simultaneously to two adjacent taps on the transformer. This results in a circulating current between these two taps. To limit this current, an impedance in the form of either resistance or inductive reactance is required. If not limited the circulating current would be a short-circuit between taps. Thus time also plays a role. Voltage change between taps is a design characteristic of the transformer, this is normally small approximately 1.25% of the nominal voltage. So if we want to do something bad, we need to make a bigger step than expected. The range seems to be somewhere between +2% and -16% in 18 steps, so quite a jump is possible if we can increase the step size.
To make it a bit more complex, a transformer can be designed with two tap changers one for in phase changes and one for out of phase changes, this also might provide us with some options to cause trouble.
So plenty of ingredients seem to be available, we need to do things in a certain sequence, we need to do it within a certain time, and we need to limit the change to prevent voltage disturbances. Step changers use a motor drive, and motor drives are controlled by motor drive units, so it looks like we have an OT function. Again a bit larger attack surface than a few sensors and a lump of metal would provide us. And then of course we saw Goose in the demo, a protocol with issues, and we have the IEDs that control all this and provide protection, a wider scope to investigate and secure but not part of the power transformer.
Is this all going to happen? I don’t think so, the Chinese company making the transformers is a business, and a very big one. If they would be caught tampering with the power transformers than that is bad for business. Can they intentionally leave some vulnerabilities in the system, theoretically yes but since multiple parties (the delivery contains also non-Chinese parts) are involved it is not likely to happen. But I have seen enough food for a more detailed analysis and inspection to find it very acceptable that also power transformers are assessed for their OT security posture when used in critical infrastructure.
So on the question are power transformers hackable, my vote would be yes. On the question will Sandia find any malicious tampering, my vote would be no. Good to run an inspection but bad to create so much fuss around it.
There is no relationship between my opinions and publications in this blog and the views of my employer in whatever capacity.
For this blog I like to go back in time, to 2017 the year of the TRISIS attack against a chemical plant in Saudi Arabia. I don’t want to discuss the method of the attack (this has been done excellently in several reports) but want to focus on the potential consequences of the attack because I noticed that the actual threat is underestimated by many.
The subject of this blog was triggered after reading Joe Weiss’ blog on the US presidential executive order and noticing that some claims were made in the blog that are incorrect in my opinion. After checking what the Dragos report on TRISIS wrote on the subject, and noticing a similar underestimation of the dangers I decided to write this blog. Let’s start with summing up some statements made in Joe’s blog and the Dragos report that I like to challenge.
I start with quoting the part of Joe’s blog that starts with the sentence: “However, there has been little written about the DCS that would also have to be compromised. Compromising the process sensors feeding the SIS and BPCS could have led to the same goal without the complexity of compromising both the BPCS and SIS controller logic and the operator displays.” The color high lights are mine to emphasize the part I like to discuss.
The sentence seems to suggest (“also have to be compromised”) that the attacker would ultimately also have to attack the BPCS to be effective in an attempt to cause physical damage to the plant. For just tripping the plant by activating a shutdown action the attacker would not need to invest in the complexity of the TRISIS attack. Once gaining access to the control system at the level the attackers did, tens of easier to realize attack scenarios were available if only a shutdown was intended. The assumption that the attacker needs the BPCS and SIS together to cause physical damage is not correct, the SIS can cause physical damage to the plant all by it self. I will explain this later with a for safety engineers well known example of an emergency shutdown of a compressor.
Next I like to quote some conclusions in the (excellent) Dragos report on TRISIS. It starts at page 18 with:
Could This Attack Lead to Loss of Life?
Yes. BUT, not easily nor likely directly.Just because a safety system’s security is compromised does not mean it’s safety function is. A system can still fail-safe, and it has performed its function. However, TRISIS has the capability to change the logic on the final control element and thus could reasonably be leveraged to change set points that would be required for keeping the process in a safe condition. TRISIS would likely not directly lead to an unsafe condition but through its modifying of a system could deny the intended safety functionality when it is needed. Dragos has no intelligence to support any such event occurred in the victim environment to compromise safety when it was needed.
The conclusion that the attack could not likely lead to the loss of life, is in my opinion not a correct conclusion and shows the same underestimation as made by Joe. As far as I am aware the part of the modified logic has never been published (hopefully someone did analyze) so the scenario I am going to sketch is just guessing a potential objective. It is what is called a cyber security hazard, it could have occurred under the right conditions for many production systems including the one in Saudi Arabia. So let’s start with explaining how shutdown mechanisms in combination with safety instrumented systems (SIS) work, and why some of the cyber security hazards related to SIS can actually lead to significant physical damage and potential loss of life.
A SIS has different functions like I explained in my earlier blogs. A little bit simplified summary, there is a preventative protection layer the Emergency Shutdown System (ESD) and there is a mitigative layer, e.g. the Fire & Gas system detecting fire or gas release and activating actions to extinguish fires and to alert for toxic gases. For our discussion I focus on the ESD function, but interesting scenarios also exist for F&G.
The purpose of the ESD system is to monitor process safety parameters and initiate a shutdown of the process system and/or the utilities if these parameters deviate from normal conditions. A shutdown function is a sequence of actions, opening valves, closing valves, stopping pumps and compressors, routing gases to the flare, etc. These actions need to be done in a certain sequence and within a certain time window, if someone has access to this logic and modifies the logic this can have very serious consequences. I almost would say, it always has very serious consequences because the plant contains a huge amount of energy (pressure, temperatures, rotational speed, product flow) that needs to be brought to a safe (de-energized) state in a very short amount of time, releasing incredible powers. If an attacker is capable of tampering with this shutdown process serious accidents will occur.
Let’s discuss this scenario in more detail in the context of a centrifugal compressor, most plants have multiple so always an interesting target for the “OT certified” threat actor. Centrifugal compressors increase the kinetic energy of for example a gas into a pressure so a gas flow through pipelines is created either to transfer a product through the various stages of the production process or perhaps to create energy for opening / closing pneumatic driven valves.
Transient operations, for example the start-up and shutdown of process equipment, always have dangers that need to be addressed. An emergency shutdown because there occurred in the plant a condition that demanded the SIS to transfer the plant to a safe state, is such a transient operation. But in this case unplanned and in principle fully automated, no process operator to guard the process and correct where needed. The human factor is not considered a very reliable factor in functional safety and is often just too slow. SIS on the other hand is reliable, the redundancy and the continuous diagnostic checks all warrant a very low failure on demand probability for SIL 2 and SIL 3 installations. They are designed to perform when needed, no excuses allowed. But this is only so if the program logic is not tampered with, the sequence of actions must be performed as designed and is systematically tested after each change.
Compressors are controlled by compressor control systems (CCS), one of the many sub-systems in an ICS. The main task of a compressor control system is anti surge control. The surge phenomenon in a centrifugal compressor is a complete breakdown and reversal of the flow through the compressor. A surge causes physical damage to the compressor and pipelines because of the huge forces released if a surge occurs. Depending on the gas this can also lead to explosions and loss of containment.
An anti surge controller of the CCS continuously calculates the surge limit (which is dynamic) and controls the compressor operation to stay away from this point of danger. This all works fine during normal operation, however when an emergency shutdown occurs the basic anti surge control provided by the CCS has shown to be insufficient to prevent a surge. In order to improve the response and prevent a surge, the process engineer has two design options called a hot bypass method or a cold bypass method recycling the gas to allow for a more gradual shutdown. The hot bypass is mostly used because of its closeness to the compressor which results into a more direct response. Such a hot bypass method requires to open some valves to feed the gas back to the compressor, this action is implemented as a task of the ESD function. The quantity of gas that can be recycled has a limit, so it is not just opening the bypass valve to 100% but opening it with the right amount. Errors in this process or a too slow reaction would easily result into a surge, damaging the compressor, potentially rupturing connected pipes, causing loss of containment, perhaps resulting in fire and explosions, and potentially resulting in casualties and a long production stop with high repair cost.
All of this is under control of the logic solver application part of the SIS. If the TRISIS attacker’s would have succeeded into loading altered application logic, they would have been capable of causing physical damage to the production installation, damage that could have caused loss of life.
So my conclusion differs a bit, an attack on a SIS can lead to physical damage when the logic is altered, which can result in loss of life. A few changes in the logic and the initiation of the shutdown action would have been enough to accomplish this.
This is just one example of a cyber security hazard in a plant, multiple examples exist showing that the SIS by itself can cause serious incidents. But this blog is not supposed to be a training for certified OT cyber terrorist so I keep it with this for safety engineers well known example.
Proper cyber security requires proper cyber security hazard identification and hazard risk analysis. This has too little focus and is sometimes executed at a level of detail insufficient to identify the real risks in a plant.
I don’t want to criticize the work of others, but do want to emphasize that OT security is a specialism not a variation on IT security. ISA published a book “Security PHA Review” written by Edwar Marsazal and Jim MgClone which addresses the subject of secure safety systems in a for me far too simplified manner by basically focusing on an analysis / review of the process safety hazop sheet to identify cyber related hazards.
The process safety hazop doesn’t contain the level of detail required for a proper analysis, neither does the process safety hazop process assume malicious intent. One valve may fail, but multiple valves at the same time in a specific sequence is very unlikely and not considered. While these options are fully open to the threat actor with a plan.
Proper risk analysis starts with identifying the systems and sub-systems of an ICS, than identifying cyber security hazards in these systems, identifying which functional deviations can result from these hazards, and than translate how these functional deviations can impact the production system. That is much more than a review of a process hazop sheet on “hackable” safeguards and causes. That type of security risk analysis requires OT security specialists with a detailed knowledge on how these systems work, what their functional tasks are, and the imagination and dose of badness to manipulate these systems in a way that is beneficial for an attacker .
Sinclair Koelemij
Cyber Physical Risk for Industrial Control Systems and process installations