For this blog, I’m focusing on a technical topic, one that’s been getting a lot of attention from the OT security community lately. There are subject matter experts like Joe Weiss who take every opportunity to point out that field equipment is not safe and therefore systems can’t be secure. For them, the security of the field device is a high priority. Others, myself included, believe that we have far more critical security vulnerabilities related to Level 1 and Level 2 functions of the process control network, and that fixing these issues reduces the overall OT security risk more than addressing a much more difficult to remedy issue. This is due to the number of field devices and the technical complexity of such an improvement, topics I will discuss in more detail in the blog.
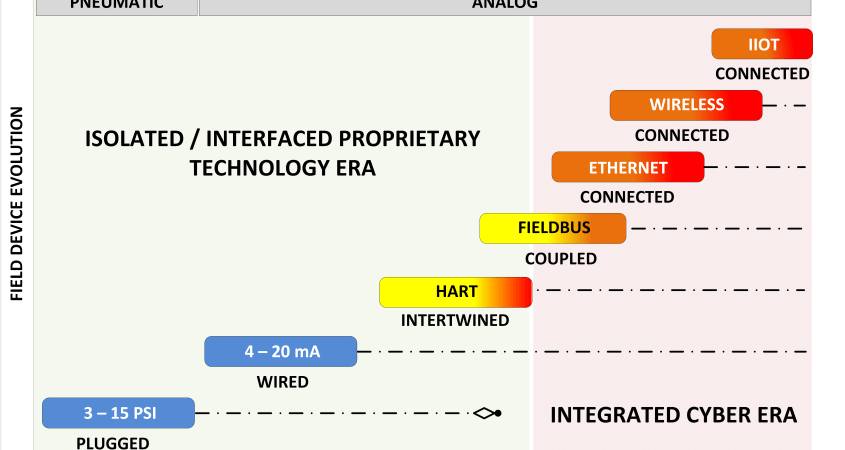
What’s the problem? First of all, we have to distinguish between two types of field devices: the “older” generation field devices that only have an analog interface, usually a 4 – 20 mA wired connection to a controller/PLC I/O board; and the intelligent devices that use digital communications, which provide the ability to remotely configure the field devices without having to be physically near the device. This offers an important safety advantage for plant personnel, of course this advantage also presents an opportunity for the threat actors to abuse this feature.
Because of the importance of field devices they can be an interesting target. In this blog I only consider the intelligent and connected devices because I consider the older generation to be secure as long as there is physical security protecting any changes using portable configurators in the field. In below diagram (FIGURE 1) I attempt to sketch the field device landscape. On the right side of FIGURE 1, which I called the cyber era, shows today’s situation. The left side of the diagram shows the isolated / interfaced proprietary technology era, not hindered by cyber attacks.
In the proprietary technology era, vendors positioned their technologies in a competitive manner from each other, while in the cyber era there is a more “collaborative environment” where different technologies are mixed and supported by multiple OT vendors through integration of different solutions. Today’s market demands that a vendor supports multiple technologies, where some of the technologies have a bigger presence in the market than others. Some technologies come close to celebrating their 40th birth day, I believe HART was introduced at the same time as the Rosemount 3051 transmitter. At that time Rosemount proprietary technology (Rosemount being an Emerson company today).


The yellow (medium) to orange to red (high) color shift indicates the growing risk due to the increasing number of attack scenarios we need to consider. The first digital protocols were introduced in the secure proprietary technology era, where systems that needed to interface with the corporate systems used serial protocols such as BSC, HDLC, and early network interfaces like DECNET. Networks were far more isolated as they are today. With the introduction of the open technology in the nineties interfacing changed to integrating, and vendors started to support a mix of technologies. This in a time were the security threat wasn’t considered in spite of the growing interconnectedness and interdependencies.
Networks were no longer isolated local networks, they became side wide networks, and today global networks connecting to the Internet and cloud services. Some technologies evolved from isolated intertwined architectures superposing a digital signal on top of an analog signal, to being used in network connected architectures where the traffic flow is less constrained than in the early days.
We see a stacking of different technologies with a different levels of attention for security. Because control systems have a long lifecycle based on a continuous evolution strategy of sometimes more than 40 years, many of these technologies are still in use. The value of the industrial property hidden in the development of decades of control applications and the high cost of replacement drives plants into this environment of a mixture of legacy and modern technologies.
Field device technologies developed 40 years ago are still in use today, while the system architectures in which these technologies are embedded, became more and more open and interconnected causing an increasing security gap that also impacts the field device security.
Can we easily secure field equipment? I often read demands for authentication, encryption, and signed software. Though some of these requirements could be met with today’s technology, many require more processing power than available today. An often used argument is to use more powerful processors, our smart watch is more powerful than any transmitter. But more powerful processors translate into requiring more electric power for the field device. But more electric power is an issue when we use these devices in industrial environments with explosive vapors. Much is done to reduce power allowing us to use these field devices safely in those environments. Environments that are quite common in the chemical and oil and gas industry, the need for intrinsic safe field devices is big, this limits the power level and so the processing power of the instrument.
There are many sides to the field device security problem, for me security doesn’t just depend exclusively on the resilience of the target. A security resilient target is nice to have, but if not available it is not the end of the story. We can and do much more to protect the field devices by for example managing the exposure of these devices to threat actors. In my opinion the security of the field devices is directly connected to the security of the level 2 and level 1 segments of the PRM. We discuss this in detail for the different field devices.
What can a threat actor do? The answer to this question depends very much on the field device technology that we discuss and how this device is used in the control and / or safety process of the plant. In this blog I limit my self to discussing three types of intelligent field devices: Transmitters / sensors; Valve positioners; and Process analyzers. If we apply these devices in a chemical or oil and gas process, a cyber failure of these devices can have serious consequences including consequences in the highest consequence rating category such as loss scenarios resulting in fatalities or physical damage to the process equipment.
To cause such a loss, requires that the threat actor creates the conditions where the production process moves into a critical state that is no longer under control by either the process operator or the safety systems. For example, a threat actor can do this by:
- Manipulating the range of a field device so that it no longer corresponds to the actual process condition;
- By turning off (setting them out of service) the field devices;
- By adjusting the control action: for a positioner (e.g. travel rate); but also for a sensor if we reverse the range;
- Or more simply by misrepresenting the actual physical state of the process (showing a low level, or a low oxygen ratio while actual values are higher) so that neither the operator nor a control program or a safety function would act in accordance with the design and/or operating intent required to prevent an unsafe state.
How can the threat actor do this? This is the actual topic of the blog, evaluating the various viable threats and what we can do and what is often already done to protect the system against these threats. For this discussion, I assume that the threat actor attacks the field equipment from an external network, and that the threat actor must therefore make extra efforts to reach the field equipment. This is not always the case when looking at the Industrial Internet Of Things (IIOT) solutions, but their application is still not as common in the refining and petrochemical industry and often used for less critical functions. IIOT and cloud security would be a different security topic, so not included in this discussion. Also when we consider malware, then we must conclude that some malware developments have shown the capability of conducting this type of attacks using scripts from inside the perimeter.
So I assume that the attacker is at an external location and attempts to attack the field devices, what are the options and which tactics, technologies, and procedures (TTP) has he/she available to succeed? In order to succeed the threat actor needs access to either level 3 (sometimes the management systems are located there) or level 2.
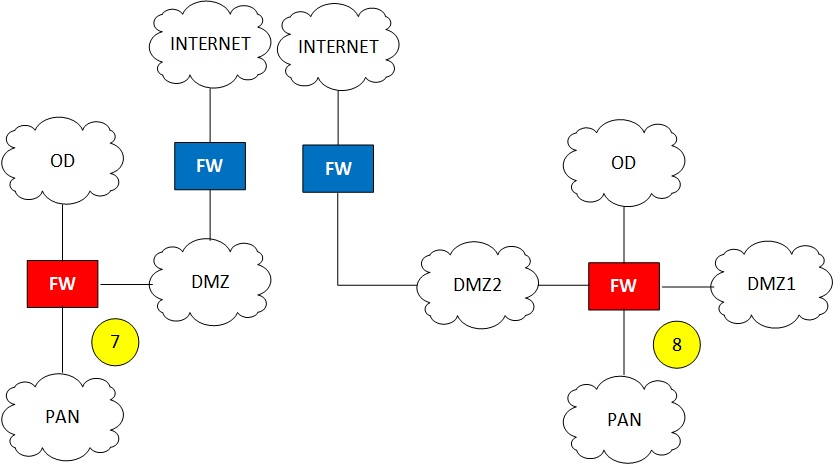
The diagram below shows a typical model of the network for a control system in the petrochemical / refining industry based on the use of a DCS (distributed control systems) and not a SCADA (as for example is the case for a pipeline). As the name already suggests, a DCS decentralizes the control functions, it is a cooperation of functions spread through the level 2 and level 1 network layers providing the overall control function. A SCADA on the other hand centralizes control functions by collecting data and taking central decisions, typically process operator controlled decisions. In a pipeline we would open and close the blocking valves and maintain a central overview with the SCADA, but the compression function in the substations is controlled using a DCS function.


The diagram is not a 1 to 1 copy of IEC 62443. With some experience in professional life you will learn that standards are a good starting point, but rarely the answer to your specific problem. Having worked in the process industry for over 40 years, including more than 20 years in networking and security, I take the liberty of deviating from time to time where I think it offers benefits or improvements.
The diagram is based on the belief that the interconnectedness, which is the basis of an IEC 62443 zone and conduit diagram, does not accurately reflect how risk spreads through a system. The factor we’re missing is interdependence, as OT security risks propagate along the lines of dependencies. In addition to mapping conduits that represent interconnectedness, I therefore also consider interdependencies. Conduits show the traffic connections between security zones, but not the dependency between functions that are several “zone hops” away. Criticality and dependency analysis is therefore an important task in risk analysis.
As an example for the relationship between dependency and security, it is not uncommon that alarm levels are determined by engineers using alarm management applications whose user interface resides in the corporate network or the demilitarized zone. These alarm levels can be enforced and overwrite the actual alarm limits at controller level. This can be critical because often safety engineers take credit for these process alarms in their LOPA safety analysis. Based on a zone and conduit diagram this dependency and neither the threats misusing the dependency would be identified. An exclusive zone and conduit focus is too limited to address the many interdependencies that exist in an automation system, it creates too much focus on the technical infrastructure connecting the components while ignoring the more important function that is distributed over many components. It is in the end the automation function that is misused by the threat actor, the technical components are primarily an instrument to do this. This function has often multiple components, making a change in a process controller can therefore happen from several components playing different roles.
This is why I added the trust levels, when there are dependencies we need to consider trust. How much can I trust being dependent on this component, what kind of dependency is it? Trust must be earned, when we interact between functions or their components at the same trust level we can accept an intrinsic form of trust. However when the gap in trust grows an enforced level of trust is needed to offer more security. Working with trust levels allows us to formulate policies for trust related to dependencies, while encapsulating the interconnectedness model provided by the zone and conduit diagram.
Zones and conduits still need to be protected, but there are two higher levels above the technical component level (functional dependencies and process dependencies) that also need to be addressed for the hazard identification step in risk analysis, the dependency and trust analysis fills this IEC 62443 gap.
Automation systems have many examples of intrinsic trust, meaning that authentication and authorization is enforced at the point where the user (process operator / engineer) enters the data and not checked anymore along the path between the source and its final destination. However there can be several components (residing in different network segments) on this path between the source and destination. This is often the cause of vulnerabilities in control systems because if the attacker finds a way to “tap” into this path (man-in-the middle attacks to manipulate the data, or either inject new messages or replay old messages) there are no more checks and the data can be manipulated resulting into an action that does neither meet design or operation intent.
Protection against these attacks is at conduit level, however to identify the hazard and specifying the security requirements requires to include the identification of these dependencies. We will see later that this is also an issue when discussing field device security.
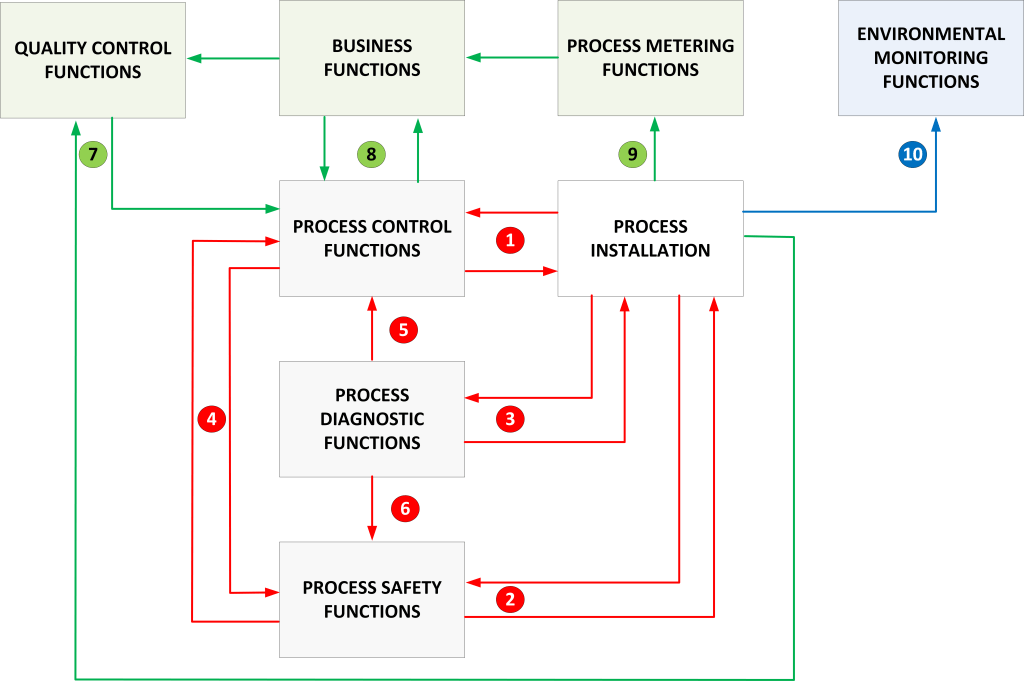
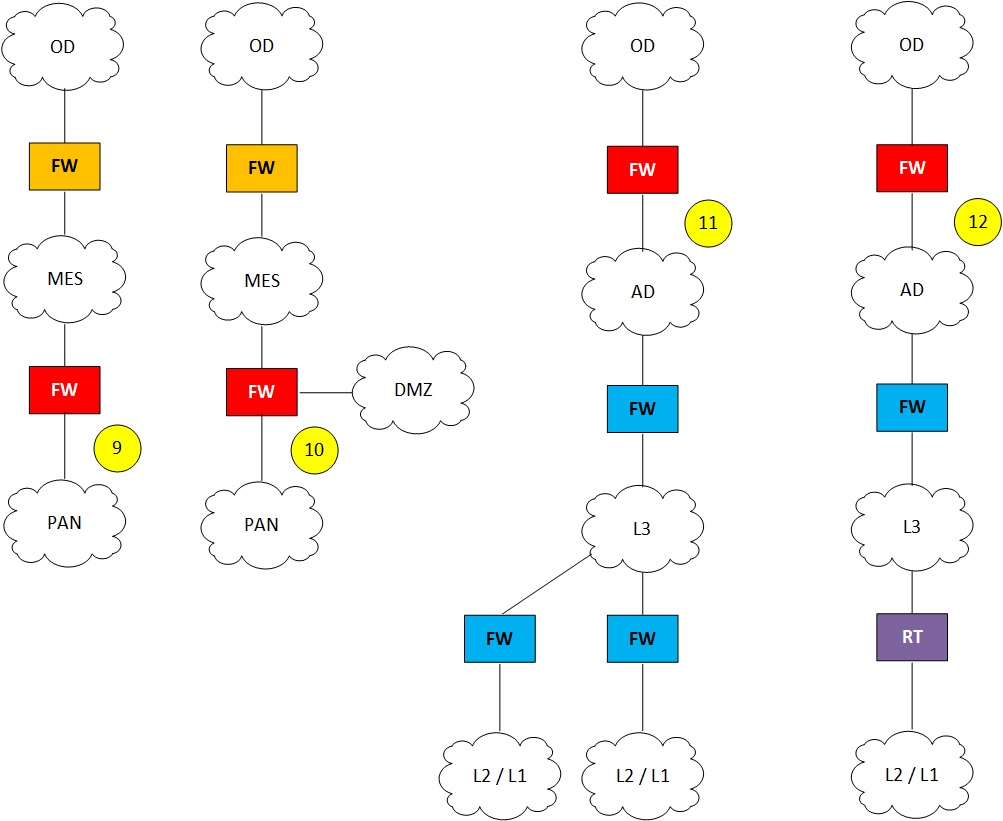
FIGURE 2 shows several network segmentation levels, the focus of our discussion will be on the levels 2, 1, and 0. This is where the attack on the field devices takes place in a properly protected system. However there are vendors that promote that the management systems reside at the level 3 of the model. This is because ISA 95 seemed to suggest this. However, ISA 95 never went into technical details for the levels 2, 1, and 0.
Managing the field devices (positioners, transmitters) and the process analyzers from level 3 is not advised because the step in trust level is more than 1. These technical management functions are better secured at level 2 of the architecture because they either need connectivity with the controllers (e.g. if HART pull through is supported) or the field equipment (e.g. if HART multiplexers are used).
Still it happens that these systems reside in the level 3 network segment because of cost savings (a single management system at level 3 can support multiple process units each with its own DCS) or DCS vendors prefer to keep 3rd party management systems outside the level 2 network segment dedicated to “their” DCS equipment. Never the less, field device and process analyzer management functions should preferably reside at level 2 and the perimeter between level 3 and level 2 should restrict access to this trusted level 2 area as much as possible. Accessing the restricted area from the level 3 network segment (jumping 2 trust levels) should never be done without additional risk controls increasing the protection of level 3 to “earn” the extra trust.
The red arrows in the conduit section of the diagram show some of the critical connections. The inbound connections from the corporate network (level 4) into the DMZ should be avoided, it is better to initiate the connection from the DMZ side so the inbound ports on the firewall can be closed by facilitating any return traffic using the stateful “awareness” functionality of the firewall. If we still need to use them because of a specific function, we should make certain that connections from the DMZ into the control network levels 3 and 2 should not use the same protocol as the inbound connection. If we have a path between the corporate network and the DMZ, toward the control network using the same protocol, a network worm compromising this protocol service can slip through the firewall and enter the control network. Connections from the DMZ toward level 2 should be prevented, never the less also here vendors have created solutions requiring them. But at minimum these cases should support an authenticated connection and enforce the same disjoint protocol rule as discussed for the connection toward the level 3 segment. The last red arrow is the connection between the level 2 segment and the level 0 segment. If it is a serial connection between a management server (for example an instrument asset management server (IAMS) connecting with a HART multiplexer) then the risk is limited, if the traffic would pass over the Ethernet to the HART multiplexer it should be protected by encryption so it becomes impossible to inject, replay, modify messages that can compromise the field devices.
It is necessary to protect the field equipment by implementing strict network access filters that block all traffic except those connections that need access. This should always be enforced for the traffic between the Level 3 and Level 2 segments, once at Level 2 there can be issues to maintain this policy because Level 2 and Level 1 segments are often a single Ethernet broadcast domain. So as such, all connected devices would be subject to a potential man-in-the-middle attack TTP, such as using ARP poisoning, or a message injection TTP. Access into level 2 can be accomplished in several ways, I will discuss this later.
The diagram also shows that I split the levels 1 and 0 into a control section and a safety section. I could have done this also for the level 2, however fully isolating the safety systems from the control systems is no longer possible. If we go back 30 years in time control systems (It is better to say the Basic Process Control System – BPCS) and safety systems (Safety Instrumented Systems – SIS) were fully isolated, even to a degree that some asset owners used different equipment rooms to isolate them as much as possible. Today this level of isolation no longer exists in the petrochemical and refining industry. Cost savings, process engineering bottlenecks (e.g. pipe length) and operation requirements have driven the solutions toward an integrated environment where process operators have a central view on the state of the control and safety functions, and where it is sometimes possible to reuse field devices for both control and safety. This all is no problem if we evaluate the process safety function along the traditional lines of availability based upon random product device failures. But we will see in the discussion that if we evaluate the process safety function including the cyber threats that the required independence of protection layers is at stake. This because the process control layer and the process safety layer have potential common points of failure due to a cyber attack, in some architectures even the independence of the preventative (ESD) and mitigation layers (F&G) of the process safety function can be impacted. We will discuss this later in the blog. The area that overlap the two level 1 and level 0 segments are drawn to express that there can be dependencies (both at functional level as well as at process level) that play a role. For example when we operate the overrides from the process operator console, or when we have 1 control transmitter combined with 2 safety transmitters in a 2oo3 architecture reducing the unavailability in order to meet a specific security integrity level (SIL), or even at the higher process level the safety valve might depend for its movement on the instrument air controlled by a compressor controlled in the control segment. Interconnectedness and dependencies are important and cause overlap that can result in common failures.
Let’s zoom in using the following more detailed diagram to explain the various threats that we have to counter in order to protect the field devices.


Perhaps a bit complex diagram because of its detail, but I created it to be able to discuss the various threats that the field devices face. The diagram shows the typical design of three field devices: a transmitter (marked A); a process analyzer (marked B); and a positioner (marked C). The diagram shows field devices with multiple interfaces, this is just for the explanation in reality a field device would typically support only one communication interface.
The other functions shown are: a process controller or alternatively a safety controller (marked H and F); a process controller (marked E); an analyzer management system (marked G); an instrument asset management system (IAMS – marked D); and a protocol converter / HART multiplexer (marked (I). The red arrows with the yellow numbers are the attack surfaces we will discuss.
From a network security perspective I discuss the HART protocol and the foundation fieldbus / Profibus protocols. These technologies are most often used, however all intelligent field devices have potential attack scenarios (see for the difference between potential and viable scenarios my earlier blog) even for those devices using the most recent technologies such as for example APL field devices. Proof of concepts have been developed for all of these during threat modelling sessions building large repositories of attack scenarios facilitating risk analysis.
Foundation Fieldbus and Profibus are in principle two different protocols but from a cyber attack perspective I can group them because they have similar characteristics from a threat actor perspective. HART transmitters can be directly connected to the control network using the HART multiplexers. The fieldbus devices always have either a controller or a gateway between the control network and the field devices. There are more differences between the two groups, and there are also differences between Foundation Fieldbus (FF) devices and Profibus devices. I will discuss those differences where applicable for a selected attack strategy / scenario.
I start with HART (the acronym for Highway Addressable Remote Transducer) a Rosemount communication protocol (presently Emerson) developed in the eighties of the previous century, so in a time cyber security for OT systems wasn’t a topic on the agenda. In the early nineties the HART Users group was formed to make the protocol an open standard for the industry. Today it is the most applied protocol in the petrochemical / refining industry for field devices. The protocol uses the traditional 4-20 mA current loop standard (introduced by Honeywell in the seventies) and superposes a Bell 202 frequency shift keying signal on top of it for the digital communication protocol. The digital communications part is a bidirectional half-duplex master-slave protocol, supporting two masters. The protocol has a relatively slow transmission rate of 1200 bits per second. The field devices can be implemented as one device per twisted pair connection, or up to 15 devices for a multidrop connection (typically RS 485 is used). When using “long form” addresses this can be extended to supporting 256 devices. The process value (PV) is communicated over the 4-20 mA current loop to the I/O card of the controller, but the HART protocol supports 3 more variables.
The digital communication also supports the exchange of the PV value, but adds three other values: Secondary Value (SV); Tertiary Value (TV); and quaternary value (QV). These values (either measured or calculated) are used to provide additional information for the device, depending on the type and function of the device.
For example, a pressure transmitter could also measure temperature, a wide range of options are available depending on the device. Normally, the communication is initiated by the master, but devices can also support burst mode, in this case the field device initiates the communication by sending messages cyclically with short pauses in between. The primary master is normally the controller, but a secondary master can be a handheld terminal or an instrument asset management system (IAMS). The master(s) exchange a series of commands with the slaves. We have three groups of commands: the universal commands (supported by all devices); common practice commands (support differs for different functions); and device specific commands (differs per device and per vendor). In total there is a maximum of 255 commands for the protocol. Though the protocol supports broadcast demands, changes to the configuration can only de done device by device.
From a protocol perspective we have the:
- Application layer (supporting the HART commands);
- Transport layer (used when we use HART over a network, this layer takes care of error handling and recovery. And the transport layer breaks up large messages in smaller size messages – TCP);
- Network layer (primarily switching and routing) using the IP protocol;
- Data link layer providing an asynchronous half duplex serial connection;
- Physical layer implemented using the Bell 202 FSK standard. HART transmitters don’t directly connect to the Ethernet, for this we need a protocol converter from Ethernet to RS 485 and a HART multiplexer to connect to multiple devices (See (I) in the diagram above).
So far the intro on the HART protocol. Let’s now discuss the attack surface for misusing this function.
HART devices are individually connected to a HART I/O card of a (either process or safety) controller or a PLC. If the device is a transmitter (A in the diagram) then the controller reads the PV directly from the 4 – 20 mA input signal, if we need access to the digital communication for reading or changing the configuration or for reading the SV/TV/QV values of the device this is possible in two ways:
- HART pull through (the controller communicates with the device and offers the data as a service to the Ethernet side, either as HART TCP protocol or encapsulated in a vendor proprietary protocol.) If a vendor proprietary protocol is used to encapsulate the HART messages authentication / encryption might be available depending on the specific vendor. The HART TCP protocol doesn’t support either authentication or encryption;
- or using a HART multiplexer that either connects serial to an instrument management device or over the Ethernet using a protocol converter.
The most secure access path is the HART pull through interface, because when this interface is used the controller generally offers various additional security settings that block write actions to the field device or require the field device to be in a maintenance mode prior to modifying configuration settings. However in some cases HART pull through is not supported, or the HART protocol is encapsulated within a vendor proprietary protocol. This results in that a management application supporting the field devices needs to make use of HART multiplexers, devices that create a multi drop bus (e.g. RS 485) connecting the devices. These multiplexers can be connected to the network using a protocol converter (See attack surfaces 1, 2, and 3). Such an architecture has a higher security risk. Let’s investigate:
- Attack surface 1 is when the protocol flows over the Ethernet, the HART protocol doesn’t offer encryption or authentication so is vulnerable for message injection, message replay, message manipulation, and message sink hole techniques. The most critical attacks are the message injection attacks from any node on the network that can reach the protocol converter. HART is routable so depending on the network segmentation such a rogue node can be everywhere. Message injection and manipulation attacks can modify in the field devices, where replay attacks can “freeze” data read from the devices. However to do this in an “intelligent” way that threat actor needs to know the internal addresses / tags of these devices. So it is not an easy approach. Another attack strategy is creating a sink hole, sink hole attacks are generally a minor issue primarily blocking the exchange of SV, TV, and QV parameters which are normally not critical.
- Attack surface 2 is the HART multiplexer, this would require physical access to connect a device to the serial bus in order to manipulate the serial data. So an insider attack, for which the likelihood is low.
- Attack surface 3 is the protocol converter, normally also of little interest because the impact would be a denial of service. However in those cases where we combine the protocol converter with a secure encrypted tunnel between the HART master and the protocol converter it can become of interest. Normally we should create a secure tunnel between the master (e.g. IAMS) and the protocol converter / multiplexer, in that case the main threat would be a denial of service, either through attacking the protocol converter (configuration changes, firmware corruption) or creating a sink hole (attack surface 1). Unfortunately many installations have installed low cost protocol converters that do not create a secure encrypted tunnel but communicate the clear text HART messages over the network. These installations are vulnerable to all attacks identified for attack surface 1.
So summarized, there are multiple options to directly attack the field devices and manipulate their configuration if we install the HART function incorrectly. We can offset the measurements by changing the ranges, or by changing tuning values / biases. But we can also reverse ranges, and so indirectly reverse control action of the process loop. Another option is to disable the field device, or upload new firmware which would allow us to carry out much more intelligent attacks or just a very simple attack the installation by uploading corrupted firmware and disabling the field device.
Technically the last attack – firmware corruption – would have the biggest impact. Theoretically we can create an attack that would disable all connected field devices. The recovery time would be significant, independent from the potential equipment damage caused by solidifying materials in process equipment and pipelines and potential loss of containment. This type of attack is shown as attack surface 11 in the diagram.
The actual impact on the production process depends on the field device type. The following are critical consequences of such an attack:
- Manipulation of the process value of a transmitter, this can result in process deviations or the possibility that a trip point of a safety controller is indirectly modified. This could initiate a wrong shutdown, or worse no shutdown if demanded. A more complex attack scenario would be to combine the attack on a safety transmitter with an attack on a process transmitter and create a process condition that could lead to critical process state. This is a difficult attack to conduct because it requires very detailed information of the process installation and its configuration, but theoretically possible and often facilitated by having both the process transmitter and the safety transmitter connected to the same HART multiplexer. Even if not used by the IAMS such a connection poses risk because of the message injection attacks. Best practices are: (1) always use tamper proof transmitters for safety transmitters that are connected to network connected HART multiplexers. This type of transmitters block write actions using a physical clip / switch; (2) don’t mix field devices of safety functions with field devices for control functions on the same HART multiplexer; (3) Consider splitting management of safety related field devices and control related field devices over multiple IAMS.
- I already mentioned the possibility to corrupt the firmware of a field device. The loss of a single field device is not a problem, field device failure happens frequently in a plant the maintenance organization can cope with that. But a massive loss of field devices can lead to a major disaster. Including scenarios with potential fatalities would be a consequence if both safety and process control devices were impacted. If this loss would be caused by corrupted field devices recovery can become a time taking and difficult job.
- Positioners is another category of field devices that can be impacted. Positioners are typically connected for monitoring valve performance (sticky valves) so generally these are positioners are part of control valves. But there are also possibilities to manage partial valve stroke tests through HART connections, this application would connect process safety valves and then the consequences can be much more severe. An attacker could modify the stroke length of the test (typically 10% but there is no limitation to set it to 100%), increasing the stroke length or initiating the test on a surprise moment, could cause a process shutdown or alternatively modify the settings of the positioner such that the valve wouldn’t move anymore or move with a too low or too high travel speed (potentially causing stress in the pipeline through water hammer). There are also valves that combine the control and safety function, though I am not aware of implementations using HART, these valves offer a series of alternative attack scenarios. But the field device market is huge, so maybe some vendors also support the HART protocol for this type of valve.
- Positioners also have firmware that can be updated, and as such corrupted to either freeze the valve position or prevent it from closing / opening when demanded. Like transmitters, positioners are critical equipment. When we decide to manage them using network connectivity we need to be careful. In all cases where HART pull through can be applied the controllers will offer additional protection mechanisms, but the moment we use connectivity based on HART multiplexers we need to be aware of the different threats discussed for attack surface 1.
HART field equipment has by far the largest market segment, approximately 80% of the field devices used in the global petrochemical and refining market are HART devices. But there are other more powerful technologies in use, depending on where you live in the world sometimes even sometimes more popular than HART devices. The second biggest market segment after HART is the Profibus segment, if I combine the three technologies Profibus PA, Profibus DP, and Profinet. Profibus was introduced in 1989 and developed over time into Profinet, the ethernet connected version. Where Profibus didn’t consider cyber security, we will see that Profinet does. Profinet is a Siemens technology and very popular outside the US. Where Europe and large parts of Asia have chosen for Profinet, the US has chosen for Ethernet/IP a Rockwell automation technology. Let’s first look at the security issues of fieldbus technologies before we look at the industrial ethernet.
When we discuss the security of fieldbus technologies, we need to address exposure. The core of OT security is managing the exposure of the many technologies used. Where IT systems are very homogeneous, OT systems are not. Perhaps all computer systems have been migrated to a the latest Microsoft release, this is normally not through for the embedded technology such as process controllers, PLCs, RTUs, safety controllers, and field devices. Also the networks are a compilation of technologies using IT like TCP/IP based networks, but also ring networks, fiber optic networks, bus networks, wireless networks, satellite connections, etc. All of them being critical for the plant, because of the many dependencies a cyber failure in one of them can lead to a scenario impacting all. By managing exposure we can attempt to contain this impact. Managing exposure is managing opportunity, the lower the exposure the lesser the opportunity. Like I explained in a previous blog, there are basically three factors that determine if a threat actor will attack these are: intent, capability, and opportunity. If any of these three are missing we are secure. By managing the exposure the defense team reduces the threat actor’s attack surface and by doing this the team also reduces the opportunity for the threat actor.


We already concluded that field devices are vulnerable because they typically do not support authentication, authorization, signed data, or encryption techniques. All of these are important security controls that would protect the field device. However it is not uncommon to be vulnerable, this happens often and is no reason to panic. There are other means of defense than increasing the resilience of the target. We can add layers of protection, shielding the target from the threat actor. By this we reduce the exposure of the target for example by choosing a specific architecture, and we can build in security mechanisms within our protection layers that function as a proxy for the protection task of the field device.


In a properly secured system this is done at a level that the field devices are better protected than the layers surrounding them. A key characteristic of security and risk is that it breaks at the weakest point in the chain. So if this point is no longer the field device we have accomplished our security task. Let’s see how this works for the field bus devices and where we have to be careful.
There are two types of interfaces between controllers / PLCs where we process the field device input or output and the field devices. We can connect the field devices to an I/O module of the control device or we can use a gateway on the control network to interconnect the field device and the controller. From an architectural point of view there is a 3rd option related to yes / no using a firewall.


An in depth Profibus (PROcess FIeld BUS) discussion is too much for the space of a blog, Profibus has many flavors with important application differences, and even my blogs shouldn’t become a book. So I focus on the three main versions, Profibus DP (Decentralized Periphery), Profibus PA (Process Automation), and an Ethernet version Profinet. I discuss the differences, starting with the two real fieldbus implementations Profibus DP and Profibus PA.
From a security perspective, these two protocols are similar, the main difference being the application of the two protocols, not so much their security resilience. Profibus DP supports faster data exchange (up to 12 Mbps) compared to Profibus PA (31.25 kbps). DP supports both mono master and multi master setup, both Profibus DP and PA are master slave protocols with different physical layers. DP communicates via a twisted pair connection (RS 485) or alternatively fiber optic link, while PA uses Manchester Bus Powered (MBP) technology. This is because PA technology is used in hazardous areas, which makes the higher power technology used by DP impossible. PA is normally used in combination with DP, as also described in Figure 6 above, the coupling device in the diagram connects the two. There is no direct communication between the master device on the DP side and the slave device on the PA side. The coupler acts as a proxy in this communication. We can connect field devices to both the DP bus and the PA bus, with the PA bus specifically intended for use in intrinsically safe environments.
From a systems exposure perspective, we have three different architectures (A, B, C). In case A, communication must be via the controller / PLC. The controller / PLC is connected to the Profibus DP bus with an I/O module. So to attack the field device, the threat actor must first attack the controller/PLC. A successful attack means a successful attack on a device that controls tens to hundreds of field devices. Once the controller/PLC is under the attacker’s control, it is no longer an advantage to take control of the field device.
In case B, a controller uses a Profibus gateway to connect to the Profibus DP network. In this case, the security of the field device depends on both the security of the message transfer between the controller and the gateway and the security of the gateway. This is often a problem because many of the protocols used at the control network level do not support encryption or authentication. This makes the architecture vulnerable to message injection, message replay, message modification, and message sink attacks. This indirectly exposes the field devices and should be considered a high-risk architecture that requires compensatory controls to protect the network segment.
In case C, the connection between the Profibus gateway and the controller is protected by a special micro firewall. This prevents the interception of the message exchange between controller and gateway on the control network. From an exposure perspective, this protects both the controller and messaging and can be considered a low-risk architecture. Of course everything depends on the firewall, if the communication through the control network with the controller uses the same protocol as the controller uses for communication with the Profibus gateway then we have scenarios that can target the controller and the risk is significantly higher . (More viable attack scenarios) Unfortunately, this is the case for several solutions on the market.
In sequence of risk (low to high) the architecture C is the most secure, and architecture B should be considered as the highest risk. But we also have to consider the maintenance and engineering functions. Profibus supports three types of masters: a DP class 1 master (MS0 (cyclic data) or MS1 (acyclic data)), a DP class 2 master (MS2), and a DP class 3 master. The class 3 master is a clock master for distributing the time. A controller or PLC is a DP class 1 master. The class 2 master is the function that is used for engineering, commissioning, and maintenance. A class 2 master is typically a PC with a dedicated engineering program capable of modifying configuration parameters in the DP slaves. In a Profibus network there is always at least one class 1 master present. The class 2 master function (D in the diagram) does not have to be online and can be connected if maintenance is required. When multiple masters are present a token is passed between the masters to control the traffic. All connected functions (masters and slaves (so also the field device)) use the Fieldbus Data Link (FDL) protocol for the exchange of process data, and there is a special Fieldbus Management (FMA) protocol for the management of the devices.


FMA 1/2 (Fieldbus management of layers 1 and 2) provides the functions necessary for configuring the field devices. We have functions such as a reset, set value (set device parameters) , read value (read device parameters), event (signals errors), Service Access Point (SAP) activate and SAP deactivate (Used for differentiation between different services in a field device, you might consider it similar to a TCP address – e.g. a get configuration service or a diagnostic service), Ident (provides hardware / software versions), LSAP status (provides configuration information on a SAP), Live-List (Kind of broadcast providing a list of all active connected bus users). Each bus user has an address on the bus, these addresses are used to communicate between the class 2 master and the slaves (field devices). Message integrity is protected by a checksum. Where in a HART environment we could inject messages toward a HART mux at control network level, in Profibus DP / PA this is more difficult because either the controller or the gateway is in between. Even in those cases where we integrate HART transmitters in a Profibus solution, we would have the Remote IO function between the field device and the controller or gateway if targeted from the control network. So we can say that no direct communication from the control network with the transmitters is possible. Attacks must be carried out through message manipulation. Only if we would manage from the Ethernet level the Profibus DP nodes using an IAMS, passing through the gateway, we also have to consider message injection attack scenarios. However many gateways have build-in protection settings to prevent this type of modification without first enabling it. Therefore the Profibus environment is less exposed as the HART environment, and if there is exposure it is more an issue of the security of the controller, gateway or remote I/O boxes than the field device.
Lets switch to discussing Profinet, Profinet is the Ethernet based standard of Profibus. Both the field devices (slaves) and class 1 and class 2 masters are Ethernet connected. So from an exposure point of view, Profinet is far more exposed than Profibus DP / PA. Profinet uses a 100 Mbps Ethernet TCP/IP backbone for its communication. Profinet supports three levels of performance:
- Engineering and other not time critical messages are transferred via TCP/IP and UDP/IP (100 ms response time – class A).
- For time-critical process data a real-time channel is created implemented through special software drivers (10 ms response time – class B);
- While for special applications such as motion control there is isochronous real-time communication with a less than 1 ms response time available- class C.
These requirements make Profinet segments very critical and therefor requires a very strict access control to prevent issues with the performance.
The network management covers all the functions for the administration of Profinet devices in Ethernet networks. These include the device and network configuration, for example, issue of IP addresses using standards like DHCP (dynamic host configuration protocol) as well as using network diagnostic messages based on standards like SNMP v2 (simple network management protocol); Integration of web functions, for example, access to components by means of standard technologies also used in the Internet field such as HTTP (hypertext transfer protocol), XML (extended mark-up language), HTML (hypertext mark-up language), and addressing with scripting; and field device integration. So all stuff that make a security guy very nervous. Profinet communicates with Profibus DP / PA devices using a proxy function (a gateway), but in this case it is direct interfacing with the field devices. The configuration is downloaded to the devices using GSD (General Station Description) files, written in xml using a special language called general station data mark-up language (GSDML).
Profinet is very susceptible to man in the middle attacks and requires a very strong access control and small segments. At this point in time Profinet offers least security of all field device protocols and for risk estimation purposes I identified more than 20 viable attack scenarios if not properly protected. More than any of the other field device protocols discussed so far.
How about Foundation Fieldbus? We have two main types of Foundation Fieldbus architectures. HSE which is based on the Ethernet technology, and the more commonly used H1 which is in many ways similar to Profibus PA.


The H1 physical layer is a 31.25 kbps version of the IEC ISA Fieldbus using a synchronous Manchester technique to allow for its use in intrinsic safe environments. Fieldbus uses a token mechanism where a token circulates between the connected devices and scheduled access based on time windows. So mixture of scheduled real-time performance and a token bus for less critical communication. The scheduling is managed by a link active scheduler node, the LAS.
From a security point of view, the data on the H1 bus is serial and unprotected. But an attacker would have to have physical access to manipulate the data. There are basically three architectures available, controllers with an FF I/O module and two architectures that use a gateway. In that regard, the three architectures discussed for FIGURE 6 (A, B, C) are also in use for FF. With exactly the same security issues, with architecture C being preferred, then architecture A, and architecture B the least secure solution.
An additional feature of FF is that it can combine the field device and control action all at H1 level. This further reduces the exposure of the solution. From a configuration point of view it has the same issues as Profibus DP.
The HSE version is Ethernet based and therefore provides a better communication performance using a 100 Mbps Ethernet cable. The benefit of HSE is that it can connect multiple H1 segments over a longer distance because the maximum length of the H1 bus is set to 120 m depending on the number of connected devices. But architectures that use Foundation Fieldbus gateways to connect a H1 segment do basically the same. If we look at the protocol stack we see many similarities with Profinet, such as the use of DHCP and SNMP (Again typically version 2 is supported). Protocols that add attack scenarios to take into account for our protection.


Like mentioned HSE is typically used to connect H1 bus segments, because Foundation Fieldbus devices can also have a control function this connection can also be used for setting up primary / secondary control structures creating peer to peer traffic between maybe a transmitter field device on one H1 segment and a control / transmitter / positioner combination on a second H1 segment. Though this is an exception, it is technically supported by the FF standard and therefor used by control engineers. The H1 Interfaces in the drawing represent the bridge configuration where the connections between the two segments are defined as a bridge making them behave as a single segment. The Virtual Field Devices (VFD) represent the field devices to be managed. The HSE LRE function (LAN Redundancy Entity) keeps track of the status of the network and its devices. It is an application layer function exchanging diagnostic messages with the various connected devices. So an interesting target to disrupt traffic. Foundation Fieldbus describes the application in terms of blocks, we have different types of blocks:
- Resource blocks – These define the fieldbus device from a hardware perspective such as specifying the manufacturer, and serial number number. But there is an additional parameter that allows us to set the device out of service, basically stopping all other functions of the device;
- Transducer blocks – This is used to configure the I/O of the devices, define such things as the sensor / actuator type, and calibration.
- Function blocks – These perform the process control functions, this can be simple analog in or analog out functions but also control algorithms such as a PID function, algorithmic functions for flow compensation, etc. All of this is defined using a Device Description Language (DDL). These device descriptors can be stored in an IAMS (Instrument Asset Management System) and uploaded / downloaded and as such manipulated by a threat actor. FF does not protect the integrity of the device descriptor other than the integrity during the data transfer against bit failures. However a device must be out of service (Resource block parameter) to change its configuration. But once done everything can be done, it is more or less equivalent to having full access to a process controller. However now in the form of a fully standardized function, no vendor specific implementation. DDL defines everything nicely independent of the vendor making the device.
Process alarms are in a foundation fieldbus environment originating in the field device, not the controller. Therefore these messages are also of interest for an attacker, creating a sink hole for this type of message can be part of an advanced attack scenario.
So HSE foundation fieldbus offers the threat actor interesting opportunities, this because we now combine control and field devices at the same level with little protection against a series of traffic manipulation attacks at Ethernet level. Before I move to the management system issues lets summarize the my conclusions with regard to sensor security. (I am aware I ignored Industrial Ethernet, too big for this already too long blog).
CONCLUSIONS ON FIELD DEVICE ARCHITECTURES
- From a field device security perspective based on exposure I consider the most secure architecture for field devices Profibus DP / PA and the Foundation Fieldbus H1 architecture. But only for the architectures A and C from FIGURE 6.
- HART is a close second as long as we have no HART multiplexers in the architecture. The main reason for me putting HART on the second place is that it is more easy to attack the field device firmware. Never the less HART without HART mux and Profibus DP/PA, Foundation Fieldbus H1 have a low probability of success for the attacker if attacked.
- PROFINET and HSE Foundation Fieldbus are considerably more exposed than above technologies (so more viable attack scenarios). Their security depends for a large part on the security of the control network segment they are connected to.
- So overall, if we consider the market size of the technologies discussed, I think the field device security is not the biggest issue. The bigger issue is in my opinion the access security to the critical control segments and the management systems discussed in the next block.
So far I looked at the field devices from an architectural perspective, how is their system exposure, how easy is it for the attacker to get access to these devices. My conclusion, see above, is that the field device exposure isn’t the biggest issue and as such the resilience of these devices against a cyber attack is not my biggest worry. But there are other paths to consider, for example the instrument asset management system (IAMS). The function we use to maintain the field devices, tune them, configure them.
In FIGURE 2, I have shown the Purdue reference model, depending on the vendor, these systems are installed at Level 2 or Level 3. First, because some IAMS functions have a much wider scope than field equipment management, they can provide a range of asset management tasks including functions for managing the process equipment such as pumps. In my opinion functions that have direct interfaces with the field devices at level 0 should be installed at level 2 to reduce their exposure. This is specifically of importance if over the network access is created with HART multiplexers.
IAMS supports Electronic Data Description (EDD) files that describe the data in the field device. Field device manufacturers create these files for managing their field devices. The IAMS reads these files in order to learn how to read and write to the device. This is a text file written in device description language (DDL). An attacker might target these files and manipulate the data in a way that these write / read activities lead to wrong results. The only security controls available to protect these files are the file system access controls. With the development of new extensions such as EDDL visualization and Persistent Data Storage threat actors have increased possibilities to mislead maintenance engineers.
A Electronic Device Description (EDD) file is used, an EDD file, written in the DDL, provides an extended description of each object in the VFD (See figure 9); it provides information needed for a control system or host to understand the meaning of the data in the VFD including the human interface for functions such as calibration and diagnostics. Thus, the EDD can be thought of as a “driver” for the device; any control system or host can operate with the device if it has the device’s EDD. EDD file is used together with a Capability File (CF) to fully describe a device.
The CF describes for a Foundation Fieldbus device the functions and the capabilities of the device; it tells the IAMS or sometimes controller or gateway what resources the device has in terms of function blocks and VCRs (Virtual Communication Relationship) etc. This allows the IAMS to configure the device even if it is not connected to it, basically you can make these files offline and store them later on the IAMS as part of the attack strategy. The idea is that the IAMS can ensure that only functions supported by the device are allocated to it, and that other resources are not exceeded. However when we manipulate these files, like mentioned only protected by their filename and directory in which they reside, this is no longer guaranteed.
Another technology used is the Field Device Manager (FDT), a function that is a container for something we call the Device Type Manager (DTM). The FDT is the common part and a software function that is part of the IAMS. The DTM is software the field device manufacturer provides. The FDT standard supports all the main field device technologies, so HART, Profibus, Foundation Fieldbus, etc. We have two types of DTMs, a device DTM supporting the communication at application level with the device and a communication DTM supporting the communication with the device (e.g. the HART protocol). Many of the DTM software is published by the manufacturer of the field device and offered as downloadable components. So in theory a supply chain attack can manipulate this software and be used to attack the field devices, but in case of the COM DTM also all other components connected to the network. An additional issue is that because a DTM runs within the FDT container not all security controls catch a non-authorized DTM.
A third technology, an integration of the EDD and FDT technologies, is the FDI (Field Device Integration) initiative. The FDI architecture is a client/server architecture based on OPC UA. OPC UA is a standard that does consider security using both authentication and encryption technology. However its day to day support is not yet big. The EDD / FDT technology is still the dominant technology in the industry.
Controllers often have read / write enable parameters for protecting the field devices against being modified. However some DTMs do not support a situation where write is disabled, this prevents frequently that we can use this control to protect the field device. This happens even in cases where from a functionality view there doesn’t seem to be a reason for writing toward the field device. So plenty of opportunity for an attacker to attack the field devices using the IAMS. This can even be more critical when we mix control and safety field device management in the same IAMS host.
I also consider process analyzer (B in FIGURE 3) as field equipment. However their exposure differs very much from the field devices such as sensors and positioners. Their interface with the process and safety controllers is typically hardwired, 4-20mA signals. The problem for process analyzers is the management interface. Traditionally analyzers had only this hard wired output, however today this is no longer true. Analyzers have become self-calibrating, self diagnosing, and add many “intelligent” functions. Though an excellent development it made them also more vulnerable to cyber attacks. To pass their information to central management systems and sometimes to the control system either serial or network network connections are used toward a management system. This management system is often placed at level 3 of the PRM (See FIGURE 2) and can be used to offset the measurements of the process analyzer. Additionally analyzer management systems might connect to the corporate network to interface with the laboratory instrument management system (LIMS). So technically we have an access path from LIMS at level 4 of the PRM to the analyzer management system at level 3, to the process analyzer at level 0. The protocol used toward the analyzers is OPC, typically classic OPC. The protocol used toward the LIMS and other users would be either HTML 5 or ODBC.
Even if analyzer networks are often separate from the control network and “dual-homed” connected through the analyzer management system this remains a risk. A dual homed connected network can easily be connected / bridged when the analyzer management system is compromised. Enabling an IP forwarding setting would connect the analyzer network to the control network if necessary for the attack, but for most attack scenarios access to the analyzer management system itself is sufficient for success.
This is critical because many analyzers have a safety function triggering a safety instrumented function if a specific concentration or ratio is too high. An additional attack surface is offered by using mobile devices that have a wireless connection with the corporate network and get their information from the analyzer management system. This makes process analyzers an interesting target often overseen.
I realize there is still a lot of unexplored territory (IIOT, Industrial Ethernet) but still I think for the chemistry/refining/oil and gas world most of the topics have been touched on. My general conclusion is that there is plenty to worry about in regards to field equipment, but most problems can be covered by having a good level of protection for the level 2 network segment. I think if we miss such good protection, we’ll be in big trouble anyway, the vulnerable field equipment doesn’t make it much worse.
There is no relationship between my opinions and references to publications in this blog and the views of my employer in whatever capacity. This blog is written based on my personal opinion and knowledge build up over 45 years of work in this industry. Approximately half of the time working in engineering these automation systems, and half of the time implementing their networks and securing them, and conducting cyber security risk assessments for process installations since 2012.
Author: Sinclair Koelemij
OTcybersecurity web site