The Ukraine crisis will almost certainly raise the cyber security risk for the of rest Europe. The sanctions imposed on Russia demand an increased awareness and defense effort for securing the OT systems. These sanctions will hurt and shall undoubtedly become an incentive for an organized revenge from very capable threat actors. What could be more effective for them than cyberattacks at a safe distance.
I think all energy-related installations such as for example port terminals, pipelines, gas distribution, and possibly power will have to raise their level of alertness. Until now, most attacks have focused on the IT systems, but that does not mean that IT systems are the only targets and the OT systems are safe. Attacking the OT systems can cause a much longer downtime than a ransomware attack or wiping disk drives would, so such an attack might be seen as a strong warning signal.
Therefor it is important to bolster our defenses. Obviously we don’t have much time, so our response should be short term, structural improvements just take too much time. So what can be done?
Let’s create a list of possible actions that we could take today if we want to brace ourselves against potential cyber attacks:
Review all OT servers / desktops that have a connection with an external network. External including the corporate network and partner networks. We should make sure that these servers have the latest security patches installed. Let’s at minimum remove the well known vulnerabilities.
Review the firewall and make certain they run the latest software version.
Be careful which side you manage the firewall from, managing from the outside is like putting your front door key under the mat.
Review all remote connections to service providers. Such connections should be free from:
Open inbound connections. An inbound channel can often be exploited, more secure remote access solutions poll the outside world for remote access requests preventing any open inbound connections.
Automatic approvals on access requests, make sure that every request is validated prior to approval for example using a voice line.
Modify your access credentials for the remote access systems, they might have been compromised in the past. Use strong passwords of sufficient length (10+) and character variation. Better is of course to combine this with two-factor authentication, but if you don’t have this today it would take too much time to add it. Would be a mid-term improvement, this list is about easy steps to do now.
Review the accounts that have access, remove stale accounts not in use.
Apply the least privilege principle. Wars make the insider threat more likely to happen, enforcing the least privilege principle will raise the hurdle.
Ensure you have session time outs implemented, to prevent that sessions remain open when they are not actively used.
Review the remote server connections. If there are inbound open ports required make sure the firewall restricts access as much as possible using at minimum IP address filters and TCP port filters. But better would be (if you have a next generation firewall in place) to add further restrictions such as restricting the access to a specific account.
Review your antivirus to have the latest signature files, the same for your IPS vaccine files.
Make certain you have adequate and up-to-date back-ups available. Did you ever test to restore a back-up?
You should have multiple back-ups, at minimum 3. It is advised to store the back-ups on at least 2 different media, don’t have both back-ups online accessible.
Make sure they can be restored on new hardware if you are running legacy systems.
Make sure you have a back-up or configuration sheet for every asset.
Hardening your servers and desk tops is also important, but if you never did this it might take some time to find out which services can be disabled and which services are essential for the server / desk top applications. So probably a mid-term activity, but reducing the attack surface is always a good idea.
Have your incident response plan ready at hand, and communicated throughout the organization. Ready at hand, meaning not on the organizational network. Have hardcopies available. Be sure to have updated contact lists and plan to have communications using non-organizational networks and resources. (Added by Xander van der Voort)
I don’t know if I missed some low hanging fruit, if so please respond to the blog so I can make the list more complete. This list should mention the easy things to do, just configuration changes or some basic maintenance. Something that can be done today if we would find the time.
Of course, our cyber worries are of a totally different order than the people in Ukraine are now experiencing for their personal survival and their survival as an independent nation. However the OT cyber community in Europe must also take responsibility and map out where our OT installations can be improved / repaired in a short time, to reduce risk.
Cyber wars have no borders, so we should be prepared.
And of course I shouldn’t forget my focus on OT risk. A proper risk assessment would bring you an insight in what threat actions (at TTP level) you can expect, and for which of these you already have controls in place. In situations like we are in now, this would be a great help to quickly review the security posture and perhaps adjust our risk appetite a bit to further tighten our controls.
However if you haven’t done a risk assessment at this level of detail today, it isn’t feasible to do this short term therefore it is not in the list. All I could do is going over the hundreds of bow-ties describing the attack scenarios and try to identify some quick wins that raise the hurdle a bit. I might have missed some, but I hope that the community corrects me so I can add them to the list. A good list of actions to bolster our defenses is of practical use for everyone.
I am not the guy that is easily scared by just another log4j story, but now I think we have to raise our awareness and be ready to face some serious challenges on our path. So carefully review where the threat actor might find weaknesses in your defense and start fixing them.
There is no relationship between my opinions and references to publications in this blog and the views of my employer in whatever capacity. This blog is written based on my personal opinion and knowledge build up over 43 years of work in this industry. Approximately half of the time working in engineering these automation systems, and half of the time implementing their networks and securing them, and conducting cyber security risk assessments for process installations since 2012.
When selecting a topic for a blog I generally pick one that entails some controversy. This time I select a topic that is generally accepted and attempt to challenge it to create the controversy. I believe very much that OT security is about learning, and that learning requires to continuously challenging the new knowledge we acquire. So this blog is not about trying to know better, or trying to refute a well founded theorem, but simply by applying some knowledge and ratio to investigate the feasibility of other options. In this case, is a one stage ICS attack feasible?
Five years ago Michael Assante and Robert Lee wrote an excellent paper called “The Industrial Control System Cyber Kill Chain“. I think the readers of this blog should carefully study this document, the paper provides a very good structure on how threat actors approach attacks on industrial control systems (ICS). The core message of the paper is that attacks on ICS, with the objective to damage production equipment, are two stage attacks.
The authors describe a first stage where the threat actor team collects information by penetrating the ICS and establishing a persistent connection, this is called in the paper the “Management and Enablement Phase“. This phase is followed by the “Sustainment, Entrenchment, Development, and Execution” phase, the phase where the threat actor captures additional information and prepares for the attack on the industrial control system (ICS).
Both phases are part of the first attack stage. The information collected in stage 1 is used to prepare the second stage in the kill chain. The second stage conducts the attack on the process installation to cause a specific failure mode (“the damage of the production system”). Typically there is considerable time between the first stage and the second stage, time used for the development of the second stage.
I assume that the rational of the authors for suggesting two stages is that each plant is unique, and as such each ICS configuration is unique, so to damage the process installation we need to know its unique configuration in detail before we can strike.
Seems like fair reasoning and the history of ICS attacks supports the theorem of two stage attacks.
Stuxnet required the threat actor team to collect information on: which variable speed drives were used to cause the necessary speed variations causing the excessive wear in the centrifuge bearings. The threat actor team also needed information on which process tags were configured in the Siemens control system to hide these speed variations from the process operator, and the threat actors required a copy of the PLC program code so they could modify it to execute the speed variations. The form of Stuxnet’s stage 1 differs probably very much from the ICS kill chain stage 1 scenario in general (Probably partially a non electronic old fashioned espionage activity), but this isn’t important. There is a stage 1 collecting information, and a stage 2 that “finishes” the job. So high level it matches the ICS kill chain pattern described in the paper.
The two attacks on the Ukraine power grid in 2015 and 2016 follow a similar pattern. It is very clear from the efficiency of the attack, developed tools and the very specific actions carried out, that the threat actor team had detailed knowledge on what equipment was installed, and which process tags were related to the breaker switches. So also in this case the threat actor team executed a stage 1 collecting information, than based on this information the threat actor team plans the stage 2 attack, and in the stage 2 attack the actual objective is realized.
The third example TRISIS / TRITON, follows the same pattern. Apparently the objective of this attack was to modify the safety integrity function in a Tristation safety controller. Details here are incomplete when reading / listening to the various sources. An interesting story, though perhaps at times a bit too dramatic for those of us that regularly spend their days at chemical plants, is for example the Darknet diaries on the TRISIS attack. Featuring among others Robert Lee and my former colleague Marina Krotofil. Was the attack directed against a Fire & Gas Tristation, or was the emergency shutdown function the target? This is not very clear in the story, because of the very different set of consequences for the production process an important detail if it comes to understanding the objective of the attack. Never the less also in the TRISIS case we saw a clear two stage approach, again an attack in two stages. First attack collecting the process information and Tristation configuration and logic, and a second attack attempting to install the modified logic and initiate (or wait for) something to happen. In my TRISIS revisited blog I explained a possible scenario to cause considerable damage and showed for this to happen that we don’t need to have a simultaneous attack on the control system.
What am I challenging in this blog? For me the million dollar question is, can an attacker cause physical equipment damage in a one stage attack, or are ICS attacks by default two stage attacks? Is a one stage attack, where all knowledge required is readily available in the public space and known by a subject matter experts, possible? And if it is a possibility, what are the characteristics that make such a scenario possible?
Personally I believe it is possible and I might even have seen an example of such an attack that I will discuss in more detail. I believe that an attacker with some basic hands-on practice working with a controls system, can do it it in a single stage.
I am not looking for scenarios that cause a loss of production, like for example a ransomware attack would cause. This is too “easy”, I am looking for targets that when attacked in the first stage would suffer considerable physical damage.
I am looking into these scenarios always for better understanding how such an attack would work and what we can learn from it to prevent such a scenario or make at least make it more difficult. Therefore I like to follow the advice of the Chinese general Sun Tzu, to learn to know the opponent, as well as our own shortcomings.
Sun Tzu wrote over 2500 years ago, the following important lesson which is also true in OT security:
“If you know the enemy and you know yourself, you don’t have to fear the result of a hundred battles.”
“If you know yourself, but not the enemy, you will also be defeated for every victory achieved.”
“If you don’t know the enemy or yourself, you will succumb in every battle.”
So lets investigate some scenarios that can lead to physical damage. In order to damage process equipment we have to focus on consequences with failure modes belonging to the categories: Loss of Required Performance and Loss of Ability (See my earlier blogs for an explanation) This since only failure modes in those categories can cause physical damage in a one stage attack.
Loss of confidentiality is basically the outcome of the first stage in a two stage attack, access credentials intellectual property (e.g. design information), or information in general all might assist in preparing stage 2. But I am looking for a single stage attack so need to rely on knowledge available in the public domain without the need to collect it from the ICS, gain access into the ICS and cause the damage on the first entry.
From a functional aspect, the type of function to attack for causing direct physical damage would be: BPCS (Basic Process Control System), SIS (Safety Instrumented System), CCS (Compressor Control System), MCC (Motor Control Center), BMS (Boiler Management System), PMS (Power Management System), APC (Advanced Process Control), CPS (Condition Protection System), and IAMS (Instrument Asset Management System).
So plenty of choice for the threat actor team depending on the objective. It is not difficult for a threat actor to find out which systems are used at a specific site and which vendor provided these functions. This because if we know the product made, we know which functions are mandatory to have. If we know the the business a bit we can find many detailed success stories on the Internet, revealing a lot of interesting detail for the threat actor team. Additionally threat actors can have access to a similar system for testing their attack strategies, such as for example the TRISIS threat actor team had access to a Triconix safety system for its attack.
To actually make the damage happen we also need to consider the failure modes of the process equipment. Some process equipment would be more vulnerable than others. Interesting candidates would be:
Extruders such as used in the thermoplastic industry, an extruder melts raw plastic, adds additives to it and passes it through a die to get the final product. This is a sensitive process where too high heath would change the product structure or an uneven flow might cause product quality issues. But the worst condition is no flow, if no flow happens this would result in that the melted plastic would solidify within the extruder. If this would happen, considerable time is required to recover from this. But this is a failure mode that happens once in a while also under normal circumstances, so an annoyance but process operations knows how to handle this so hardly an interesting target for a cyber attack attempting to cause significant damage.
How about a kiln in a cement process? If a kiln doesn’t rotate, the construction would collapse under its own weight. So stopping a kiln could be a potential target, however it is not that complex to create a safeguard creating a manual override to bypass the automation system to keep the kiln rotating. So also not an interesting target to pursuit for this blog.
How about a chemical process where runaway reactions are a potential failure mode? A runaway reaction is a thermally unstable reaction that accelerates with rising temperature and can ultimately lead to explosions and fires. A relatively recent example of such an accident is the Shell Moerdijk accident in 2014. Causing a runaway reaction could certainly be a scenario because these can be induced relatively easy. The threat actor team wouldn’t need that much specific information to carry out the attack, they could perhaps stop the agitator in the reactor vessel, or stop a cooling process to trigger the runaway reaction. If the threat actor gained access to the control system, this action is not that complex to do if familiar with control systems. So for me a potential single stage attack target.
Another example that came to mind was the attack on the German steel mill in 2014. According to the BSI report the attacker(s) gained access into the office network through phishing emails, once the threat actor had access into the office network they worked their way into the control systems. How this happened is not documented, but could have been through some key logger software. Once the threat actor had access to the control system they caused what was called “an uncontrolled shutdown” by shutting down multiple control system components. This looks like a one stage attack, lets have a closer look.
LESSON 1: Never allow access from the office domain into the control domain without implementing TWO-FACTOR AUTHENTICATION. Not even for your own personnel. Not implementing two-factor implementation is denying the risk of phishing attacks and ignoring defense in depth. When doing so we are taking a considerable risk. See also my blog on remote access, RULE 3.
For the steel mill attack there are no details known on what happened other than that the threat actor according to the BSI report shuts down multiple control system components and causes massive damage. Just speculating from now on what might have happened but a possible scenario could have been shutting down shutting down the cooling system and shutting down BPCS controllers so the operator can’t respond that quickly. The cooling system is one of the most critical parts of a blast furnace. Because the BSI report mentions both “Anlagen” and “Steurungskomponenten” it might have been above suggestion, first shutting down the motors of the water pumps and than shutting down the controllers to prevent a quick restart of the pumps.
The picture on the left (Courtesy of HSE) shows a blast furnace. A blast furnace is charged at the top with iron ore, coke, sinter, and limestone. The charge materials gradually work their way down, reacting chemically and thermally on their path down. This process takes about 6-8 hours depending on the size of the furnace. The furnace is heated by injecting hot air (approx. 1200 C) mixed with pulverized coal, and sometimes methane gas through nozzles called Tuyeres in the context of a blast furnace.
This results in a furnace temperature of over 2000 C. To protect the blast furnace shell against these high temperatures it is critical to cool the refractory lining (See picture). This cooling is done by pumping water into the lining. Cooling systems are typically fully redundant having doubled all equipment.
There would be multiple electrical pump systems and turbine (steam) driven pump systems. If one system fails, the other would take immediately over. One being steam driven, the other being electrical driven. So all looks fine from a cooling system failure perspective. The problem is that when we consider OT cyber security we also have to consider malicious failures / forced shutdowns. In those cases redundancy doesn’t work multiple motors can be switched of, neither is it so that if a process valve fails to a closed or open position there might not be another valve doing the same or in opposite direction. Frequently we see in process safety HAZOP analysis that double failures are not taken into account, this is the field of the cyber security HAZOP translating the various failure modes of the ICS functions in how they can be used to cause process failures.
The question in above scenario is could the attacker shutdown both pumps, and would there be a manual restart of the cooling system possible. If this would fail, the lining would overheat very quickly. In the case of a Corus furnace in Port Talbot, the cooling system was designed to run simultaneously two pumps, each producing 45.000 litres per minute. So a flow equivalent to 90.000 1 liter water bottles per minute. If we would need a crowd of people to consume this amount of water per minute, we get a very sizable crowd. Just to give you an idea how much water this is. If the cool water flow was stopped, the heat in the lining would rise very quickly and as a result the refractory lining would be damaged through the huge thermal stress created.
For safety purposes there is generally also an emergency water tower which acts when the water pressure drops. This system supplies water through gravitational force, it might not have worked, or maybe insufficient capacity to prevent damage. Or perhaps the attacker also knew a way to stop this safety control.
Do we need a two-stage attack for above scenario?
I believe a threat actor with sufficient hands-on experience with a specific BPCS, can relatively quickly locate these critical pumps and could shut them down. With the same level of knowledge he can subsequently shutdown the controller if his authorizations would allow this. Typically engineer level access would be required, but I also encountered systems were process operators could shutdown a controller. How blast furnaces work and what the critical functions are, even which companies specialize in supplying these functions is all in the public domain. So perhaps a single stage attack is possible.
If above is a credible scenario on what might have happened in the case of the German steel mill, what can we learn from it and do to increase the resilience against this attack?
First, we should not allow any remote access (access from the corporate network is also remote access) without two-factor authentication if the user would have “write” possibilities in the ICS. The fact that an attacker could gain access into the corporate network and from there could get access into the control network and causing an uncontrolled shutdown is in my opinion a significant (and basic) security flaw.
Second, we should consider implementing dual control for critical functions in the process that have a steady state. For example a compressor providing instrument air, or in this case a cool water pump and its redundant partners that should be on as the normal state. Dual control would demand that two users approve the shutdown action before the control system executes the command, this would generally be users with a different authorization level. Such a control would further raise the bar for the threat actor.
LESSON 2: For critical automation functions that can cause significant damage when initiated, consider to either isolate them from the control system (hardwired connections) or implement DUAL CONTROL to not only depend on a single layer of protection – access control. Defense in depth should never be ignored for critical functions, WHEN CRITICAL DON’T RELY ON A SINGLE CONTROL, APPLY DEFENSE IN DEPTH!
Above two additional security controls would make the sketched scenario much more difficult, almost impossible to succeed. OT security is more than installing AV, patching and a firewall. To reduce risk we need to assess security from all points of view: the automation function and its vulnerabilities, our protection of these vulnerabilities, our situational awareness of what is happening, and what threats there are – which attack scenarios could happen.
IEC 62443 specifies the “dual control” requirement as an SL 4 requirement, I personally consider this as a flaw in the standard and believe it should already be a mandatory requirement for SL 3 because unauthorized access to critical process equipment is well within the capabilities of the “sponsored attacker” type of threat actor.
Having dual control as a requirement doesn’t mean that all control actions should have this implemented, but there are critical functions in a plant that are seldom switched on or off where adding dual control adds security by adding DEFENSE IN DEPTH. When critical, don’t rely on a single control.
Also today’s blog is a story on the need for approaching OT security of ICS in a different manner as we do for IT systems where network security and hardening are the core activities for prevention. Network security and hardening of the computer systems are also essential first steps for an OT system but we should never forget the actual automation functions of the OT systems.
This is why OT security teams should approach OT security differently and construct bow-tie diagrams for cyber security hazards, relating cause (threat actor initiating threat action exploiting a vulnerability) to consequence (the functional deviation) and identifying security countermeasures, safeguards, and barriers. Only following this path we can analyze possible process failures as result of a functional deviation and can design OT systems in a secure way. However for this method to provide the required information we need a far higher level of detail / discrimination than terminology used in the past offered. Terminology such as loss of view and loss of control don’t lead to identifying countermeasures, safeguards and barriers. To make a step toward how a cyber attack can impact a production system we need much more granularity, therefor the 16 failure modes discussed in a prior blog.
Each ICS main function (BPCS, SIS, CCS, PMS, ….) has a fixed set of functions and potential deviations, it is the core task of the cyber security HAZOP to identify what risk they bring. Not to identify these deviations, these are fixed because each main function has a set of automation tasks it carries out. It are the deviations, their likelihood and severity for the production installation that are of importance, because than we know what benefits controls bring and which controls are of less importance. But we need to consider all options before we can select.
LESSON 3 – My final lesson of the day, first analyze what the problem is prior to trying to solve it.
Many times I see asset owners surfing the waves of the latest security hype. Every security solution has its benefits and “exciting” features, but this doesn’t mean it is the right solution for your specific problem or addressing your biggest security gap.
To know what are the right solutions you need to have a clear view on the cyber security hazards in your system, and then priority and select those that contribute most. There are often many features already available, start using them.
This leads to reusing methodologies we have learned to apply successfully for almost 60 years now in process safety, we should adapt them where necessary and reuse them for OT security.
There is no relationship between my opinions and references to publications in this blog and the views of my employer in whatever capacity. This blog is written based on my personal opinion and knowledge build up over 42 years of work in this industry. Approximately half of the time working in engineering these automation systems, and half of the time implementing their networks and securing them.
In times of Covid-19 the interest in remote access solutions has grown. Remote access has always been a hot topic for industrial control systems, some asset owners didn’t want any remote access, others made use of their corporate VPN solutions to create access to the control network, and some made use of the remote access facilities provided by their service providers. In this blog I will discuss a set of security controls to consider when implementing remote access.
There are multiple forms of remote access:
Remote access from an external organization, for example a service provider. This requires interactive access, often with privileged access to critical ICS functions;
Remote access from an internal organization, for example process engineers, maintenance engineers and IT personnel. Also often requires privileged access;
Remote operations, this provides the capability to operate the production process from a remote location. Contrary to remote access for support this type of connection requires 24×7 availability and should not hinder the process operator to carry out his / her task;
Remote monitoring, for example health monitoring of turbines and generators, well head monitoring and similar diagnostic and monitoring functions;
Remote monitoring of the technical infrastructure for example for network performance, or remote connectivity to a security operation center (SOC);
Remote updates, for example daily updates for the anti-virus signatures, updates for the IPS vaccine, or distribution of security patches.
The rules I discuss in this blog are for remote interactive access for engineering and support tasks, a guy or girl accessing the control system from a remote location for doing some work.
In this discussion I consider a remote connection to be a connection with a network with a different level of “trust”. I put “trust” between quotes because I don’t want to enter in all kind of formal discussions on what trust is in security, perhaps even if we should allow trust in our life as security professional.
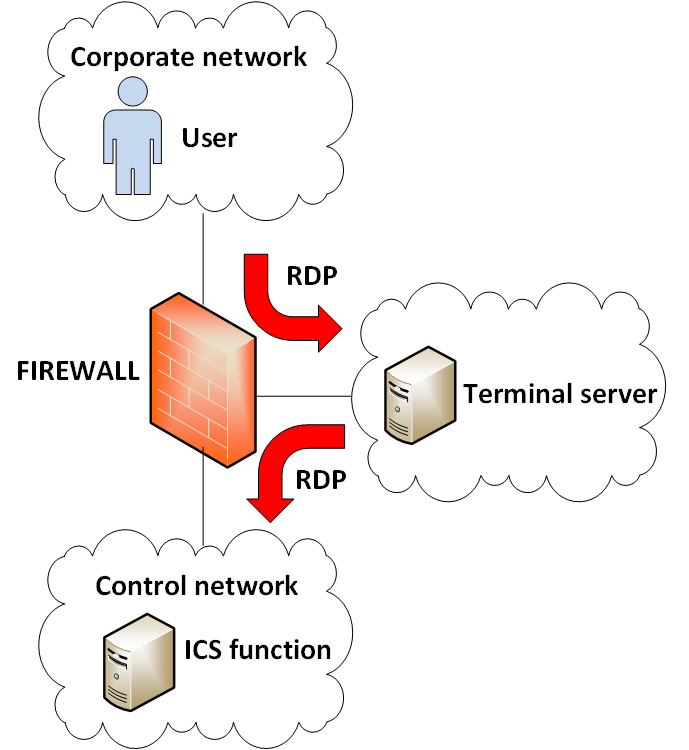
RULE 1 – (Cascading risk) Enforce disjoint protocols when passing a DMZ.
The diagram shows a very common architecture, but unfortunately also one with very high risk because of allowing inbound access into the DMZ toward the terminal server and allowing outbound access from the terminal server to the ICS function using the same protocol.
Recently we have had several RDP vulnerabilities that were “wormable”, meaning a network worm can make use of the vulnerability to propagate through the network. So allowing a network worm that infects the corporate network to reach the terminal server and from there infect the control network. Which is high risk in times of ransomware spreading as a network worm.
This is a very bad practice and should be avoided! Not enforcing disjoint protocols increases what is called cascading risk, the risk that a security breach propagates through the network.
RULE 2 – (Risk of hacking) Prevent inbound connections. Architectures where the request is initiated from the “not-trusted” side, like in above terminal server example, require an inbound firewall port to be open to facilitate the traffic. For example in above diagram the TCP port for the RDP protocol.
Solutions using a polling mechanism, where a function on the trusted side polls a function on the not-trusted side for access requests, offers a smaller attack surface because the response channel makes use of the firewall’s stateful behavior, where the port is only temporarily open for just this specific session.
Inbound connections expose the service that is used, if there would be a vulnerability in this service this might be exploited to gain access. Prevent at all times such connections coming from the Internet. Direct Internet connectivity requires a very good protection, an inbound connection for remote access offers a high risk for compromise.
So also a very bad practice, unfortunately a practice I came across to several times because some vendor support organizations use such connectivity.
RULE 3 – (Risk of exposed login credentials) Enforce two-factor authentication. The risk that the access credentials are revealed through phishing attacks capturing the access credentials is relatively big. Two factor authentication adds to this the requirements that apart from knowing the credentials (login / password) the threat actor also needs to possess access to a physical token generator for login.
This raises the bar for a threat actor. Personally I have the most trust in a physical token like a key fob that generates a code. Alternatives are tokens installed in the PC, either as software or as a USB device.
RULE 4 – (Risk of unauthorized access) Enforce an explicit approval mechanism where someone on the trusted side of the connection explicitly needs to “enable” remote access. Typically after a request over the phone either the process operator / supervisor or a maintenance engineer needs to approve access before the connectivity can be established.
Multiple solutions exist, some solutions have this feature build-in, sometimes an Ethernet switch is used, and there are even firewalls where a digital input signal can alter the access rule.
Sometimes implicit approval seems difficult to prevent, for example access to sub-sea installations, access to installations in remote areas, or access to unmanned installations. But also for these situations implementing explicit approval is often possible with some clever engineering.
RULE 5 – (Risk of prohibited traffic) Don’t allow for end to end tunneled connections between a server in the control network and a server at the not trusted side (either corporate network or a service provider network)
Encrypted tunnels prevent the firewall to inspect the traffic, so bypass more detailed checks on the traffic. So best practice is to break the tunnel have it inspected by the firewall and reestablish the tunnel to the node on the trusted side of the network. Where to break the tunnel is often a discussion, my preference is to break it in the DMZ. Tunneled traffic might contain clear text communication, so we need to be careful where to expose this traffic if we open the tunnel.
RULE 6 – (Risk of unauthorized activity) Enforce for connectivity with external users, such as service providers, a supervision function where someone on the trusted side can see what the remote user does and intervene when required.
Systems exist that no only supervise the activity visual, but also log all activity allowing it to be replayed later in time.
RULE 7 – (Risk of unauthorized activity) Make certain there is an easy method to disconnect the connection. A “supervisor” on the trusted side (inside) of the connection must be able to disconnect the remote user. But prevent that this can be done accidentally, because if the remote user does some critical activity, his control over the activity shouldn’t be suddenly lost.
RULE 8 – (Risk of unauthorized activity) Restrict remote access to automation system nodes as much as possible. Remote access to a safety engineering function might not be a good idea, so prevent this where possible. Where in my view this should be prevented with a technical control, an administrative policy is fine but generally not considered by an attacker.
RULE 9 – (Risk of unauthorized access) Restrict remote access for a limited time. A remote access session should be granted for a controlled length of time. The time duration of the session needs to match the time requirement of the task, never the less there should be an explicit end time that is reasonable.
RULE 10 – (Risk of exposure confidential data) Enforce the use of secure protocols for remote access, login credentials should not pass the network in clear text at any time. So for example don’t use protocols such as Telnet for accessing network devices, use the SSH protocol that encrypts the traffic instead.
In principle all traffic that passes networks outside the trusted zones should be encrypted and end to end authenticated. Using certificates is a good option, but it better be a certificate specifically for your plant and not a globally used certificate.
In times of state sponsored attackers, the opponent might have the same remote access solution installed and inspected in detail.
RULE 11 – (Risk of exposure confidential data) Don’t reveal login credentials of automation system functions to external personnel from service providers. Employees of service providers generally have to support tens or hundreds of installations. They can’t memorize all these different access credentials, so quickly mechanism are used to store these. Varying from paper to Excel spreadsheets and password managers, prevent that a compromise of this information compromises your system. Be aware that changing passwords of services is not always an easy task, so control this cyber security hazard.
A better approach might be to manage the access credentials for power users, including external personnel, using password managers that support login as a proxy function. In these systems the user only needs to know his personnel login credentials and the proxy function will use the actual credentials in the background. This has several security advantages:
Site specific access credentials are not revealed, if access is no longer required, disabling / removing access to the proxy function is sufficient to block access without ever having compromised the system’s access credentials.
Enforcing access through such a proxy function blocks the possibility of hopping between servers, because the user is not aware of the actual password. (This does require to enforce certain access restrictions for users in general.)
Also consider separating the management of login credentials for external users from the management of login credentials for internal users (users with a login on the trusted side). You might want to differentiate between what a user is allowed to do remotely and what he can do when on site. Best to enforce this with technical controls.
RULE 12 – (Risk of unauthorized activity) Enforce least privilege for remote activities. Where possible only provide view-only capabilities. This often requires a collaborative session where a remote engineer guides a local engineer to execute the actions, however it reduces the possibilities for an unauthorized connection to be used for malicious activity.
RULE 13 – (Risk of unauthorized activity) Manage access into the control network from the secure side, the trusted side. Managing access control and authorizations from the outside of the network is like putting your door key outside under the doormat. Even if the task is done from remote, the management systems should be on the inside.
RULE 14 – (Risk of unauthorized activity) Detection. Efi Kaufman addressed in a response a very valid point.
We need to build our situational awareness. The whole idea of creating a DMZ zone is to have one zone where we can do some detailed checks before we let the traffic in. In RULE 5, I already mentioned to break the tunnel open so we can inspect, but there is of course lots more to inspect. If we don’t apply detection mechanisms we have an exclusive focus on prevention assuming everyone behaves fine when we open the door.
This is unfortunately not true, so a detection mechanism is required to check if nothing suspicious happens. Exclusively focusing on prevention is a common trap, and I fell in it!
Robin, a former pen tester pointed out that it is important to monitor the antivirus function, as pentester he was able to compromise a system, because av triggering on the payload was not monitored, giving him all the time to investigate and modify the payload until it worked.
RULE 15 – (Risk of hacking, cascading risk) Patching, patching, patching. There is little excuse not to patch remote access systems, or systems in the DMZ in general. Exposure demands that we patch.
Beware that these systems can have connectivity with the critical systems, their users might be logged in using powerful privileges, privileges that could be misused by the attacker. Therefore patching is also very important.
RULE 16 – (Risk of malware infection, cascading risk) Keep your AV up to date. While we start to do some security operation tasks, better to make sure our AV signatures are up to date.
RULE 17 – (Risk unauthorized activities) Robin addressed in a response the need for enforcing that the remote user logs for each request the purpose of the remote access request. This facilitates identification if processes are followed, and people are not abusing privileges or logging in daily for 8 hours/day for a month instead of coming to site.
Seventeen simple rules to consider when implementing remote access that popped up in my mind while typing this blog.
If I missed important controls please let me know than I will add them.
Use these rules when considering how to establish remote connectivity for support type of tasks. Risk appetite differs, so engineers might only want to select some rules and accept a bit higher risk.
But Covid-19 should not lead to an increased risk of cyber incidents by implementing solutions that increase exposure on the automation systems in an irresponsible manner.
There is no relationship between my opinions and publications in this blog and the views of my employer in whatever capacity.