The Ukraine crisis will almost certainly raise the cyber security risk for the of rest Europe. The sanctions imposed on Russia demand an increased awareness and defense effort for securing the OT systems. These sanctions will hurt and shall undoubtedly become an incentive for an organized revenge from very capable threat actors. What could be more effective for them than cyberattacks at a safe distance.
I think all energy-related installations such as for example port terminals, pipelines, gas distribution, and possibly power will have to raise their level of alertness. Until now, most attacks have focused on the IT systems, but that does not mean that IT systems are the only targets and the OT systems are safe. Attacking the OT systems can cause a much longer downtime than a ransomware attack or wiping disk drives would, so such an attack might be seen as a strong warning signal.
Therefor it is important to bolster our defenses. Obviously we don’t have much time, so our response should be short term, structural improvements just take too much time. So what can be done?
Let’s create a list of possible actions that we could take today if we want to brace ourselves against potential cyber attacks:
Review all OT servers / desktops that have a connection with an external network. External including the corporate network and partner networks. We should make sure that these servers have the latest security patches installed. Let’s at minimum remove the well known vulnerabilities.
Review the firewall and make certain they run the latest software version.
Be careful which side you manage the firewall from, managing from the outside is like putting your front door key under the mat.
Review all remote connections to service providers. Such connections should be free from:
Open inbound connections. An inbound channel can often be exploited, more secure remote access solutions poll the outside world for remote access requests preventing any open inbound connections.
Automatic approvals on access requests, make sure that every request is validated prior to approval for example using a voice line.
Modify your access credentials for the remote access systems, they might have been compromised in the past. Use strong passwords of sufficient length (10+) and character variation. Better is of course to combine this with two-factor authentication, but if you don’t have this today it would take too much time to add it. Would be a mid-term improvement, this list is about easy steps to do now.
Review the accounts that have access, remove stale accounts not in use.
Apply the least privilege principle. Wars make the insider threat more likely to happen, enforcing the least privilege principle will raise the hurdle.
Ensure you have session time outs implemented, to prevent that sessions remain open when they are not actively used.
Review the remote server connections. If there are inbound open ports required make sure the firewall restricts access as much as possible using at minimum IP address filters and TCP port filters. But better would be (if you have a next generation firewall in place) to add further restrictions such as restricting the access to a specific account.
Review your antivirus to have the latest signature files, the same for your IPS vaccine files.
Make certain you have adequate and up-to-date back-ups available. Did you ever test to restore a back-up?
You should have multiple back-ups, at minimum 3. It is advised to store the back-ups on at least 2 different media, don’t have both back-ups online accessible.
Make sure they can be restored on new hardware if you are running legacy systems.
Make sure you have a back-up or configuration sheet for every asset.
Hardening your servers and desk tops is also important, but if you never did this it might take some time to find out which services can be disabled and which services are essential for the server / desk top applications. So probably a mid-term activity, but reducing the attack surface is always a good idea.
Have your incident response plan ready at hand, and communicated throughout the organization. Ready at hand, meaning not on the organizational network. Have hardcopies available. Be sure to have updated contact lists and plan to have communications using non-organizational networks and resources. (Added by Xander van der Voort)
I don’t know if I missed some low hanging fruit, if so please respond to the blog so I can make the list more complete. This list should mention the easy things to do, just configuration changes or some basic maintenance. Something that can be done today if we would find the time.
Of course, our cyber worries are of a totally different order than the people in Ukraine are now experiencing for their personal survival and their survival as an independent nation. However the OT cyber community in Europe must also take responsibility and map out where our OT installations can be improved / repaired in a short time, to reduce risk.
Cyber wars have no borders, so we should be prepared.
And of course I shouldn’t forget my focus on OT risk. A proper risk assessment would bring you an insight in what threat actions (at TTP level) you can expect, and for which of these you already have controls in place. In situations like we are in now, this would be a great help to quickly review the security posture and perhaps adjust our risk appetite a bit to further tighten our controls.
However if you haven’t done a risk assessment at this level of detail today, it isn’t feasible to do this short term therefore it is not in the list. All I could do is going over the hundreds of bow-ties describing the attack scenarios and try to identify some quick wins that raise the hurdle a bit. I might have missed some, but I hope that the community corrects me so I can add them to the list. A good list of actions to bolster our defenses is of practical use for everyone.
I am not the guy that is easily scared by just another log4j story, but now I think we have to raise our awareness and be ready to face some serious challenges on our path. So carefully review where the threat actor might find weaknesses in your defense and start fixing them.
There is no relationship between my opinions and references to publications in this blog and the views of my employer in whatever capacity. This blog is written based on my personal opinion and knowledge build up over 43 years of work in this industry. Approximately half of the time working in engineering these automation systems, and half of the time implementing their networks and securing them, and conducting cyber security risk assessments for process installations since 2012.
The question I raise in this blog is: “Can we reduce risk by reducing consequence severity?” Dale Peterson touched upon this topic in his recent blog.
It has been a topic I struggled with for several years, initially thinking “Yes, this is the most effective way to reduce risk”, but now many risk assessments (processing thousands of loss scenarios) later I come to the conclusion it is rarely possible.
If we visualize a risk matrix with horizontally the likelihood and vertically the consequence severity, we can theoretically reduce risk by either reducing the likelihood or the consequence severity. But is this really possible in today’s petro-chemical, refining, or oil and gas industry? Let’s investigate.
If we want to reduce security risk by reducing consequence severity, we need to reduce the loss that can occur when the production facility fails due to a cyber attack. I translate this in we need to create an inherently safer design.
This topic is already a very old topic addressed by Trevor Kletz and Paul Amyotte in their book “A handbook for inherently Safer Design, 2nd edition 2010”. This book is based on an even earlier work (Cheaper, safer plants, or wealth and safety at work: notes on inherently safer and simpler plants – Trevor Kletz 1984) from the mid-eighties which shows that the drive to make plants inherently safer is a very old objective and a very mature discipline. Are there any specific improvements to the installation that we did not consider necessary from a process safety point of view, but should be done from an OT security point of view?
Let’s look at the options we have. If we want to reduce the risk induced by the cyber threat we can approach this in several ways:
Improve the technical security of the automation systems, all the usual stuff we’ve written a lot of books and blogs about – Likelihood reduction;
Improve automation design, use less vulnerable communication protocols, use more cyber-resilient automation equipment – Likelihood reduction;
Improve process design in a way that the threat actor has less options to cause damage. For example do we need to connect all functions to a common network so we can operate them centrally, or is it possible to isolate some critical functions making an orchestrated attack more difficult – Likelihood / consequence reduction;
Reduce the plant’s inventory of hazardous materials, so if something would go wrong the damage would be limited. This is what is called intensification/minimization – Consequence reduction;
An alternative for intensification is attenuation, here we use a hazardous material under the least hazardous conditions. For example storing liquefied ammonia as a refrigerated liquid at atmospheric pressure instead of storage under pressure at ambient temperature – Consequence reduction;
The final option we have is what is called substitution, in this case we select safer materials. For example replacing a flammable refrigerant by a non-flammable one – Consequence reduction.
So theoretically there are four options that reduce consequence severity. In the past 30 years the industry has invested very much in making plants more safe. There are certainly still unsafe plants in the world, partially a regional issue / partially lack off regulations, but in the technologically advanced countries these inherent unsafe plants have almost fully disappeared.
This is also an area where I as OT security risk analyst have no influence, if I would suggest in a cyber risk report that it would be better for security risk reduction to store the ammonia as a refrigerated liquid they would smile and ask me to mind my own business. And rightfully so, these are business considerations and the cyber threat is most likely a far less dangerous threat than the daily safety threat.
Therefor the remaining option to reduce consequence severity seems to be to improve process design. But can we really find improvements here? To determine this we have to look at where do we find the biggest risk and what causes this risk?
Process safety scenarios where we see the potential for severe damage are for example: pumps (loss of cooling, loss of flow), compressors, turbines, industrial furnaces / boilers (typically ignition scenarios), reactors (run-away reactions), tanks (overfilling), and the flare system. How does this damage occur? Well typically by stopping equipment, opening or closing valves / bypasses, manipulating alarms / measurements/positioners, overfilling, loss of cooling, manipulating manifolds, etc.
A long list of possibilities, but primarily secured by protecting the automation functions. So a likelihood control. The process equipment impacted by a potential cyber attack are there for a reason. I never encountered a situation where we identified a dangerous security hazard and came to the conclusion that the process design should be modified to fix it. There are cases where a decision is taken not to connect specific process equipment to the common network, but this is also basically a likelihood control.
Another option is to implement what we call Overrule Safety Control (OSC) this is a layer of safety instrumentation, which cannot be turned off or overruled by anything or anybody. When the process conditions enter a highly accident-prone, life-safety critical state such as for example the presence of hydrogen in a sub-merged nuclear reactor containment (mechanically open the enclosure to flood the containment with water) or the presence of methane on an oil drilling rig, an uninterruptible emergency shutdown is automatically triggered. However this is typically a mechanical or fully isolated mechanism because as soon as it has an electronic / programmable component it can be hacked if it would be network connected. So I consider this solution also as a yes/no connection decision.
I don’t exclude the possibility that situations exist where we can manage consequence severity, but I haven’t encountered them in the past 10 years analyzing OT cyber risk in the petro-chemical, refining, oil & gas industry apart from these yes / no connect questions. The issues we identified and addressed were always automation system related issues, not process installation issues.
Therefor I think that consequence severity reduction, though the most effective option if it would be possible, is not going to bring us the solution. So we end up focusing on improving automation design and technical security managing the exposure of the cyber vulnerabilities in these systems, Dale’s suggested alternative strategy seems not feasible.
So to summarize, in my opinion there is not really an effective new strategy available by focusing on reducing cyber risk by managing consequence severity.
There is no relationship between my opinions and references to publications in this blog and the views of my employer in whatever capacity. This blog is written based on my personal opinion and knowledge build up over 43 years of work in this industry. Approximately half of the time working in engineering these automation systems, and half of the time implementing their networks and securing them, and conducting cyber security risk assessments for process installations since 2012.
Are there rules an engineer must follow when executing a new project? This week Yacov Haimes passed away at the age of 86 years. Haimes was an American of Iraqi decent and a monument when it comes to risk modeling of what he called systems of systems. His many publications among which his books “Modeling and Managing Interdependent Complex Systems of Systems” (2019) and “Risk Modeling, Assessment, And Management” (2016) provided me with a lot of valuable insights that assisted me to execute and improve quantitative risk assessments in the process industry. He was a man who tried to analyze and formalize the subjects he taught and as such created some “models” that helped me to better understand what I was doing and guide me along the way.
Readers that followed my prior blogs know that I consider automation systems as Systems of Systems (SoS) and have discussed these systems and their interdependencies and interconnectedness (I-I) often in the context of OT security risk. In this blog I like to discuss some of these principles and point to some of the gaps I noticed in methods and standards used for risk assessments conflicting with these principles. To start the topic I introduce a model that is a merger between two methods, on one side the famous 7 habits of Covey and on the other side a system’s development process, and use this model as a reference for the gaps I see. Haimes and Schneiter published this model in a 1996 IEEE publication, I kind of recreated the model in Visio so we can use it as a reference.
A holistic view on system’s engineering Haimes and Schneiter (C) 1996 IEEE
I just pick a few points per habit where I see gaps between the present practice advised by standards of risk engineering / assessment and some practical hurdles. But I like to encourage the reader to study the model in far more detail than I cover in this short blog.
The first Stephen Covey habit is, habit number 1 “Be proactive” and points to the engineering steps that assist us in defining the risk domain boundaries and help us to understand the risk domain itself. When we start a risk analysis we need to understand what we call the “System under Consideration”, the steps linked to habit 1 describe this process. Let’s compare this for four different methods and discuss how these methods implement these steps, I show them above each other in the diagram so the results remain readable.
Four risk methods
The ISO 31000 is a very generic model, that can be used both for quantitative risk assessment as well as qualitative risk assessment. (See for the definitions of risk assessments my previous blog) The NORSOK model is a quantitative risk model used for showing compliance with quantitative risk criteria for human safety and the environment. The IEC/ISA 62443.3.2 model is a generic or potentially a qualitative risk model specifically constructed for cyber security risk as used by the IEC/ISA 62443 standard in general. The CCPS model is a quantitative model for quantitative process safety analysis. It is the 3rd step in a refinement process starting with HAZOP, then LOPA, and if more detail is required than CPQRA.
Where do these four differ if we look at the first two habits of Covey? The proactive part is covered by all methods, though CCPS indicates a focus on scenarios, this is primarily so because the HAZOP covers the identification part in great detail. Never the less for assessing risk we need scenarios.
An important difference between the models rises from habit 2 “Begin with the end”. When we engineer something we need clear criteria, what is the overall objective and when is the result of our efforts (in the case of a risk assessment and risk reduction, the risk) acceptable?
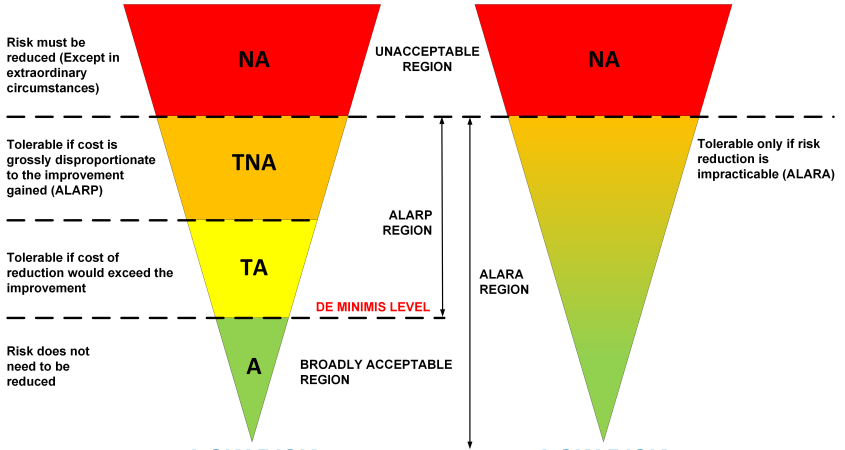
This is the first complexity and strangely enough are these criteria a hot topic between continents, my little question “when is risk acceptable?” is for many Americans an unacceptable question, the issue is their legal system which mixes “acceptability” and “accountability” so they translate this into “when is risk tolerable”. However the problem here is that there are multiple levels for tolerable. European law is as usual diverse, we have countries that follow the ALARP principle (As Low As Reasonably Practical) and we have countries that follow the ALARA principle (As Low As Reasonably Achievable). ALARP has a defined “DE MINIMIS” level, kind of a minimum level where we can say risk is reduced to a level that is considered an acceptable risk reduction by a court of law. Contrary to ALARA where we need to reduce the risk to the level it is no longer practicable, so there is no cost criterium but only a pure technical criterium.
ALARP, ALARA comparison
For example the IEC/ISA 62443-3-2 standard compares risk with the tolerable level without defining what that level is. For an ALARA country (e.g. Germany, Netherlands) that level is clearly defined by the law and the IEC / ISA interpretation (stopping further risk reduction at this level) would not be acceptable, for an ALARP country (e.g. UK) the limits and conditions are also well defined but cost related. The risk reduction must go all the way to the DE MINIMUS level if cost would allow it. Which is in cyber security for a chemical plant often the case, this because the cost of a cyber incident – that can cause one or multiple fatalities – in the UK this cost is generally higher than the cost of the cyber security measures that could have prevented it. The cost of a UK fatality is set to approx. 1.5 million pound, actually an American is triple that cost 😊according to the US legal system, the Dutch and Germans (being ALARA) are of course priceless.
So it is important to have clear risk acceptance criteria established and objectives when we start a risk assessment. If we don’t – such as is the case for IEC/ISA 62443.3.2 comparing initial and residual risk with some vaguely defined tolerable risk level – the risk reduction most likely fails a legal test in a court room. ALARP / ALARA are also legal definitions, and cyber security also needs to meet these. Therefore the step risk planning is an essential element of the first NORSOK step and in my opinion should always be the first step, engineering requires a plan towards a goal.
Another very important element according Haines is the I-I (interdependencies, interconnectedness) element. Interconnectedness is covered by IEC/ISA 624433.2 by the zone and conduit diagram, conduits connect zones, though these conduits are not necessarily documented at the level allowing us to identify connections within the zone that can be of relevance for cyber risk (consider e.g. ease of malware propagation within a zone).
Interdependencies are ignored by IEC/ISA 62443. The way to identify these interdependencies is typically conducting a criticality analysis or a Failure Mode and Effect Analysis (FMEA). Interdependencies propagate risk because the consequence of function B might depend on the contribution of function A. A very common interdependency in OT is when we take credit in a safety risk analysis for both a safeguard provided by the SIS (e.g. a SIF) and a safeguard provided by the BPCS (e.g. an alarm), if we need to reduce risk with a factor 10.000, there might be a SIL 3 SIF defined (factor 1000) and the BPCS alarm (factor 10). If a cyber attack can disable one of the two the overall risk reduction fails. Disabling process alarms is relatively easy to do with a bit of ARP poisoning, so from a cyber security point of view we have an important interdependency to consider.
Habit 1 and 2 are very important engineering habits, if we follow the prescriptions taught by Haines we certainly shouldn’t ignore the dependencies when we analyze risk as some methods do today. How about habit 3? This habit is designed to help concentrate efforts toward more important activities, how can I link this to risk assessment?
Especially when we do a quantitative risk assessment vulnerabilities aren’t that important, threats have an event frequency and vulnerabilities are merely the enablers. If we consider risk as a method that wants to look into the future, it is not so important what vulnerability we have today. Vulnerabilities come and go, but the threat is the constant factor. The TTP is as such more important than the vulnerability exploited.
Of course we want to know something about the type of vulnerability, because we need to understand how the vulnerability is exposed in order to model it, but if we yes/no have a log4j vulnerability is not so relevant for the risk. Today’s log4j is tomorrow’s log10k. But it is essential to have an extensive inventory of all the potential threats (TTPs) and how often these TTPs have been used. This information is far more accessible than how often a specific exposed (so exploitable) vulnerability exists. We need to build scenarios and analyze the risk per scenario.
Habit 4 is also of key importance, win-win makes people work together to achieve a common goal. The security consultant’s task might be to find the residual risk for a specific system, but the asset owner typically wants more than a result because risk requires monitoring, risk requires periodic reassessment. The engineering method should support these objectives in order to facilitate the risk management process. Engineering should always consider the various trade-offs there are for the asset owner, budgets are limited.
Habit 5 “Seek first to understand, then to be understood” can be directly linked to the risk communication method and linked to the perspective of the asset owner on risk. So reports shouldn’t be thrown over the wall but discussed and explained, results should be linked to the business. Though this might take considerably more time it is never the less very important.
But not an easy habit to acquire as engineer since we often are kind of nerds with an exclusive focus on “our thing” expecting the world to understand what is clear for us. One of the elements that is very important to share with the asset owner are the various scenarios analyzed. The scenario overview provides a good insight in what threats have been evaluated (typically close to 1000 today, so a sizeable document of bow-ties describing the attack scenarios and their consequences) and the overview allows us to identify gaps between the scenarios assessed and the changing threat landscape.
Habit 6 “Synergize”, is to consider all elements of the risk domain but also their interactions and dependencies. There might be influences from outside the risk domain not considered, never the less these need to be identified another reason why dependencies are very important. Risk propagates in many ways, not necessarily exclusively over a network cable.
Habit 7 “Sharpen the saw”, if there is one discipline where this is important than it is cyber risk. The threat landscape is in continuous movement. New attacks occur, new TTP is developed, and proof of concepts published. Also whenever we model a system, we need to maintain that model, improve it, continuously test it and adjust where needed. Threat analysis / modelling is a continuous process, results need to be challenged, new functions added.
Business managers typically like to develop something and than repeat it as often as possible, however an engineering process is a route where we need to keep an open eye for improvements. Habit 7 warns us against the auto-pilot. Risk analysis without following habit 7 results in a routine that doesn’t deliver appropriate results, one reason why risk analysis is a separate discipline not just following a procedure as it still is for some companies.
There is no relationship between my opinions and references to publications in this blog and the views of my employer in whatever capacity. This blog is written based on my personal opinion and knowledge build up over 43 years of work in this industry. Approximately half of the time working in engineering these automation systems, and half of the time implementing their networks and securing them, and conducting cyber security risk assessments for process installations since 2012.
This blog is about risk assessment in cyber physical systems and some of the foundational principles. I created several blogs on the topic of risk assessment before, for example “Identifying risk in cyber physical systems” and “ISA 62443-3-2 an unfettered opinion“. Specifically the one on criticizing the ISA standard caused several sharp reactions. In the meantime ISA 62443-3-2 has been adopted by the IEC and a task group focusing on cyber security and safety instrumented systems (ISA 84 work group 9) addresses the same topic. Though unfortunately the ISA 84 team seems to have the intention to copy the ISA 62443-3-2 work and with this also the structural flaws will enter the work of this group. One of these flaws is the ISA approach toward likelihood.
Therefore this blog addresses this very important aspect of a risk assessment in the cyber physical system arena. Likelihood is actually the only factor of interest, because the impact (severity of the consequences) is a factor that the process hazard analysis the asset owner makes provides. Therefore likelihood / probability is the most important and challenging variable to determine because many of the cyber security controls affect the likelihood of a cyber security hazard occurring. Much of the risk reduction is achieved by reducing the chance that a cyber attack will succeed through countermeasures.
Having said this about likelihood we must not ignore the consequences, as I have advocated in previous blogs. This because risk reduction through “cyber safeguards” (those barriers that either eliminate the possibility of a consequence occurring or reduce the severity of that consequence – see my earlier blogs) is often a more reliable risk reduction than “cyber countermeasures” (those barriers that reduce the likelihood).
But this blog is about likelihood, the bottlenecks we face in estimating the probability and selecting the correct quantitative scale to allow us to express a change in process safety risk as the result of the cyber security threat.
At the risk of losing readers before coming to the conclusions, I would still like to cover this topic in the blog and explain the various problems we face. If you are interested in risk estimation I suggest to read it, if not just forward it to stalk your enemies.
Where to start? It is always dangerous to start with a lot of concepts because for part of the audience this is known stuff, while for others it answers some questions they might have. I am not going to give much formulas, most of these have been discussed in my earlier blogs, but it is important to understand there are different forms of risk. These forms often originate from different questions we like to answer. For example we have:
Risk priority numbers (RPN), is a risk value used for ranking / prioritization of choices. This risk is a mathematical number, the bigger the number the bigger the risk;
Loss based risk (LBR), is a risk used for justifying decisions. This risk is used in production plants and ties the risk result to monetary loss due to production outage / equipment damage / permit to operate. Or a loss expressed in terms of human safety or environmental damage. Often risk is estimated for multiple loss categories;
Temporal risk or actuarial risk, is a risk used for identifying the chance on a certain occurrence over time. For example insurance companies use this method of risk estimation analyzing for example the impact of obesity over a 10 year period to understand how it impacts their cost.
There are more types of risk than above three forms, but these three cover the larger part of the areas where risk is used. The only two I will touch upon in this blog, are RPN and LBR. Temporal risk, the question of how many cyber breaches caused by malware will my plant face in 5 years from now, is not raised today in our industry. Actually at this point in time (2021) we couldn’t even estimate this because we lack the statistical data required to answer the question.
We like to know what is the cyber security risk today, what is my financial, human safety, and environmental risk, can it impact my permit to operate, and how can I reduce this risk in the most effective way? What risk am I willing to accept and what should I keep a close eye on, and what risk will I avoid? RPN and LBR estimates are the methods that provide an answer here and both are extensively used in the process industry. RPN primarily in asset integrity management and LBR for business / mission risk. LBR is generally derived from the process safety risk, but business / mission risk is not the same as process safety risk.
Risk Priority Numbers are the result of what we call Failure Mode Effect and Criticality Analysis (FMECA) a method applied by for example asset integrity management. FMECA was developed by the US military over 80 years ago to change their primarily reactive maintenance processes into proactive maintenance processes. The FMECA method focuses on qualitative and quantitative risk identification for preventing failure, if I would write “for preventing cyber failure” I create the link to cyber security.
For Loss Based Risk there are various estimation methods used (for example based on annual loss expectancy), most of them very specific for a business and often not relevant or not applied in the process industry. The risk estimation method mostly used today in the process industry, is the Layers Of Protection Analysis (LOPA) method. This method is used extensively by the process safety team in a plant. The Hazard and Operability (HAZOP) study identifies the various process hazards, and LOPA adds risk estimation to this process to identify the most prominent risks.
If we know what process consequences can occur (for example a seal leak causing an exposure to a certain chemical, yes / no potential ignition, how many people would be approximately present in the immediate area, is the exposure yes / no contained within the fence of the plant, etc.) we can convert the consequence into a monetary/human safety/environmental loss value. This together with the LOPA likelihood estimate, results in a Loss Based Risk score.
How do we “communicate” risk, well generally in the form of a risk assessment matrix (RAM). A matrix that has a likelihood scale, an impact scale and shows (generally using different colors) what we see as acceptable risk, tolerable risk, and not acceptable risk zones. But other methods exist, however the RAM is the form most often used.
A picture of a typical risk assessment matrix with 5 different risk levels and some criteria for risk appetite and risk tolerance. And a picture to have at least one picture in the blog.
So much for the high-level description, now we need to delve deeper into the “flaws” I mentioned in the introduction / abstract. Now that the going gets tough, I need to explain the differences between low demand mode and high demand / continuous mode as well as the differences between IEC 61511 and IEC 62061 and some differences in how the required risk reduction is estimated, but also how the frequency of events scale ,underlying the qualitative likelihood scale, plays a role in all this. This is a bit of a chicken and egg problem, we need to understand both before understanding the total. Let me try, I start with taking a deeper dive into process safety and the safety integrity limit – the SIL.
In process safety we start with what is called the unmitigated risk, the risk inherent to the production installation. This is already quite different from cyber security risk, where unmitigated risk would be kind of a foolish point to start. Connected to the Internet and without firewalls and other protection controls, the process automation system would be penetrated in milli-seconds by all kind of continuous scanning software. Therefor in cyber security we generally start with residual risk based upon some initial countermeasures and we investigate if this risk level is acceptable / tolerable. But let’s skip a discussion on the difference between risk tolerance and risk appetite, a difference ignored by IEC 62443-3-2 though from a risk management perspective an essential difference that provides us time to manage.
However in plants the unmitigated situation is relevant, this has to do with what is called the demand rate and that we don’t analyze risk from a malicious / intentional perspective. Incidents in process safety are accidental, caused by wear and tear of materials and equipment, human error. No malicious intent, in a HAZOP sheet you will not find scenarios described where process operators intentionally open / close valves in a specific construction/sequence to create damage. And typically most hazards identified have a single or sometimes a double cause, but not much more.
Still asset owners like to see cyber security risk “communicated” in the same risk assessment framework as the conventional business / mission risk derived from process hazard analysis. Is this possible? More to the point, is the likelihood scale of a cyber security risk estimate the same as the likelihood scale of a process safety risk estimate if we take the event frequencies underlying the often qualitative scales of the risk diagrams into account?
In a single question, would the qualitative likelihood score of Expected for a professional boxer to go knock out (intentional action) during the job during his career, be the same as for a professional accountant (accidental)? Can we measure these scales along the same quantitative event frequency scales? I don’t think so. Even if we ignore for a moment the difference in career length, the probability that the accountant goes knock out (considering he is working for a reputable company) during his career is much lower. But the IEC/ISA 62443-3-2 method does seem to think we can mix these scales. But okay, this argument doesn’t necessarily convince a process safety or asset integrity expert, even though they came to the same conclusion. To explain I need to dive a little deeper into the SIL topic in the next section and discuss the influence of another factor, demand rate, on the quantitative likelihood scale.
The hazard (HAZOP) and risk assessment (LOPA) are used in process safety to define the safety requirements. The safety requirements are implemented using what are called Safety Instrumented Functions (SIF). The requirements for a SIF can be seen as two parts:
Safety function requirements;
Safety integrity requirements;
The SIFs are implemented to bring the production process to a safe state when demands (hazardous events) occur. A demand is for example if the pressure in a vessel rises above a specified limit, the trip point. The safety functional requirements specify the function and the performance requirements for this function. For example the SIF must close an emergency shutdown valve the “Close Flow” function, performance parameters can be the closing time and the leakage allowed in closed position. For this discussion the functional requirements are not that important, but the safety integrity requirements are.
When we discuss safety integrity requirements, we can split the topic into four categories:
Performance measures;
Architectural constraints;
Systematic failures;
Common cause failures.
For this discussion the performance measures, expressed as the Safety Integrity Level (SIL), are of importance. For the potential impact of cyber attacks (some functional deviation or lost function) the safety function requirements (above), and the common cause failures, architectural constraints, and systematic failures are of more interest. But the discussion here focuses on risk estimation and more specific the likelihood scale not so much on how and where a cyber attack can cause process safety issues. Those scenarios can be discussed in another blog.
The safety integrity performance requirements define the area I focus on, in these requirements safety integrity performance is expressed as a SIL. The IEC 61508 defines 4 safety integrity levels: SIL 1 to SIL 4. SIL 4 having the most strict requirements. To fulfill a SIL, the safety integrity function (SIF) must meet both a quantitative requirement and a set of qualitative requirements.
According to IEC 61508 the quantitative requirement is formulated based on either an average probability of failure on demand (PFDavg) for what are called low demand SIFs, and a Probability of Failure on Demand per Hour (PFH) high demand / continuous mode SIFs. Two different event frequency scales are defined, one for the low demand SIFs and one for the high demand SIFs. So depending on how often the protection mechanism is “challenged” the risk estimation method will differ.
For the low demand SIFs the SIL expresses a range of risk reduction values, and for the high demand SIFs it is a scale of maximum frequency of dangerous system failures. Two different criteria, two different methods / formulas for estimating risk. If the SIF is demanded less than once a year, low-demand mode applies. If the SIF is demanded more than once a year high demand / continuous mode is required. The LOPA technique for estimating process safety risk is based upon the low-demand mode, the assumption that the SIF is demanded less than once a year. If we would compare our cyber security countermeasure with a SIF, will our countermeasure be demanded just once a year? An antivirus countermeasure is demanded every time we write to disk, not to mention a firewall filter passing / blocking traffic. Risk estimation for cyber security controls is high demand / continuous mode.
LOPA specifies a series of initiating event frequencies (IEF) for various occurrences. These event frequencies can differ between companies, but with some exceptions they are similar. For example the IEF for a control system sensor failure can be set to once per 10 year, and the IEF for unauthorized changes to the SIF can be set to 50 times per year. These are actual examples for a chemical plant, values from the field not an example made up for this blog. The 50 seems high, but by giving it a high IEF it also requires more and stronger protection layers to reduce the risk within the asset owner’s acceptable risk criteria. So there is a certain level of subjectivity in LOPA possible, which creates differences between companies for sometimes the same risk. But most of the values are based on statistical knowledge available in the far more mature process safety discipline compared with the cyber security discipline.
In LOPA the IEF is reduced using protection layers (kind of countermeasure) with a specific PFDavg. PFDavg can be a calculated value, carried out for every safety design, or a value selected from the LOPA guidelines, or an asset owner preferred value.
For example an operator response as protection layer is worth a specific factor (maybe 0.5), so just by having an operator specified as part of the protection layer (maybe a response to an alarm) the new frequency, the Mitigated Event Frequency (MEF), for the failed control system sensor becomes 0.5 x 10 equivalent to once per 5 years. Based upon one or more independent protection layers with their PFD, the IEF is reduced to a MEF. If we create a linear scale for the event frequency and sub-divide the event scale in a number of equal qualitative intervals to create a likelihood scale, we can estimate the risk given a specific impact of the hazardous event. The linearity of the scale is important since we use the formula risk equals likelihood times impact, if the scale would be logarithmic the multiplication wouldn’t work anymore.
In reality the LOPA calculation is a bit more complicated because we also take enabling factors into account, probability of exposure, and multiple protection layers (including BPCS control action, SIF, Operator response, and physical protection layers such as brake plates and pressure relief valves). But the principle to estimate the likelihood remains a simple multiplication of factors. However LOPA applies only for the low demand cases and LOPA is using an event scale based on failures of process equipment and human errors. Not an event scale that takes into account how often a cyber asset like an operator station gets infected by malware, not taking into account intentional events, and starts with the unmitigated situation. Several differences with risk estimation for cyber security failures.
Most chemical and refinery processes follow LOPA and qualify for low-demand mode, with a maximum demand for a SIF of once a year. However in the offshore industry there is a rising demand for SIL based on high demand mode. Also in the case of machinery (IEC 62061) a high demand / continuous mode is required. Using high demand mode results in a different event scale, different likelihood formulas and LOPA no longer applies. Now let us look at cyber security and its likelihood scale. When we estimate risk in cyber physical systems we have to account for this, if we don’t a risk assessment might be a learning exercise because of the process it self but translating the results on a loss based risk scale would be fake.
Let us use the same line of thought used by process safety and translate this into the cyber security language. We can see a cyber attack as a Threat Actor applying a specific Threat Action to Exploit a Vulnerability, resulting in a Consequence. the consequence being a functional deviation of the target’s intended operation if we ignore cyber attacks breaching the confidentiality and focus on attacks attempting to impact the cyber physical system.
The threat actor + threat action + vulnerability combination has a certain event frequency, even if we don’t know yet what that frequency is, there is a certain probability of occurrence. That probability depends on many factors. Threat actors differ in capabilities and opportunity (access to target), also the exploit difficulties of a vulnerability differ and on top of all we protect these vulnerabilities using countermeasures (the protection layers in LOPA) we need to account for. We install antivirus to protect us against storing a malware infected file on the hard disk, we protect us against repeated logins that attempt brute force authentication by implementing a retry limit, we protect us against compromised login credentials by installing two factor authentication, etc. A vulnerability is not just a software deficiency, but also an unused open port on a network switch, or unprotected USB port on a server or desktop. There are hundreds of vulnerabilities in a system, each waiting to be exploited. There are also many cyber countermeasures, each with a certain effectiveness, each creating a protection layer. And with defense in depth we generally have multiple protection layers protecting our vulnerabilities. A very similar model as discussed for LOPA. This was recognized and a security method ROPA (Rings of Protection Analysis) was developed for physical security. Using the same principles to get a likelihood value based upon an event frequency.
Though ROPA was initially developed for physical security, this risk estimation method is and can also be used for cyber security. What is missing today is a standardized table for the IEF and the PFD of the various protection controls. This is not different from ROPA and LOPA because for both methods there is a guideline, but in daily practice each company defined its own list of IEF and PFDavg factors.
Another important difference with process safety is that cyber and physical security require like machinery a high demand / continuous mode which alters the risk estimation formulas (and event scales!), but the principles remain the same. So again the event frequency scale for cyber events differs from the event frequency scale used by LOPA. The demand rate for a firewall or antivirus engine is almost continuous, not limited to once a year like in the low demand mode of LOPA for process safety and derived from this business / mission risk.
The key message in above story is that the event scale used by process safety, for risk estimation is based upon failures of primarily physical equipment and accessories such as sealings and human errors. Where the event scale of cyber security is linked to the threat actor’s capabilities (Tactics, Techniques, Procedures), motivation, resources (Knowledge, money, access to equipment), opportunity (opportunities differ for an insider and outsider, some attacks are more “noisy” than others), it is linked to the effectiveness of the countermeasures (ease of bypassing, false negatives, maintenance), and the exposure of the vulnerabilities (directly exposed to the threat actor, requiring multiple steps to reach the target, detection mechanisms in place, response capabilities). These are different entities, resulting in different scales. We cannot ignore this when estimate loss based risk.
Accepting the conclusion that the event scales differ for process safety and for cyber security is accepting the impossibility to use the same risk assessment matrix for showing cyber security risk and process safety risk as is frequently requested by the asset owner. The impact will be the same, but the likelihood will be different and as such the risk appetite and tolerance criteria will differ.
So where are the flaws in IEC/ ISA 62443-3-2?
Starting with an inventory of the assets and channels in use is always a good idea. The next step, the High Level Risk Assessment (HLRA) is in my opinion the first flaw. There is no information available after the inventory to estimate likelihood. So it is suggested the method to set the likelihood to 1, basically risk assessment becomes a consequence / impact assessment at this point in time. An activity of the FMECA method. Why is a HLRA done, what is the objective of the standard? Well it is suggested that these results are later used to determine if risk is tolerable, if not a detailed risk assessment is done to identify improvements. It is also seen as a kind of early filter mechanism, focusing on the most critical impact. Additionally the HLRA should provide input for the zone and conduit analysis.
Can we using consequence severity / impact determine if the risk is tolerable (a limit suggested by ISA, the risk appetite limit is more appropriate than the risk tolerance limit in my view)?
The consequence severity is coming from the process hazard analysis (PHA) of the plant, so the HAZOP / LOPA documentation. I don’t think this information links to the likelihood of a cyber event happening. I give you a silly example to explain. Hazardous event 1, some one slaps me in the face. Hazardous event 2, a roof tile hits me on my head. Without the knowledge of likelihood (event frequency), I personally would consider the roof tile the more hazardous event. However if I would have some likelihood information telling me slapping me in the face would happen every hour and the roof tile once every 30 years I might reconsider and regret having removed hazard 1 from my analysis. FMECA is a far more valuable process than the suggested HLRA.
Does a HLRA contribute to the zone and conduit design? Zone boundaries are created as a grouping of assets with similar security characteristics following the IEC 62443 definition. Is process impact a security characteristic I can use to create this grouping? How can I relate a tube rupture in a furnace’s firebox to my security zone?
Well, then we must first ask ourselves how such a tube rupture can occur. Perhaps caused by a too high temperature, this I might link to a functional deviation caused by the control system or perhaps it might happen as the consequence that a SIF doesn’t act when it is supposed to act. So I may link the consequence to a process controller or maybe a safety controller causing a functional deviation resulting in the rupture. But this doesn’t bring me the zone, if I would further analyze how this functional deviation is caused I get into more and more detail, very far away from the HLRA. An APC application at the level 3 network segment could cause it, a modification through a breached BPCS engineering station at level 2 could cause it, an IAMS modifying the sensor configuration can cause it, and so on.
Security zone risk can be estimated in different ways, for example as zone risk following the ANSSI method. Kind of risk of the neighborhood you live in. We can also look at asset risk and set the zone risk equal to the asset with the highest risk. But all these methods are based on RPN, not on LBR.
HLRA’s just don’t provide valuable information, we typically use them for early filtering making a complex scope smaller. But that is neither required, nor appropriate for cyber physical systems. Doing a HLRA helps the risk consultant not knowing the plant or the automation systems in use, but in the process of estimating risk and designing a zone and conduit diagram it has no added value.
As next step ISA 62443-3-2 does a detailed risk assessment to identify the risk controls that reduce the risk to a tolerable level. This is another flaw because a design should be based upon an asset owner’s risk appetite, which is the boundary of the acceptable risk. The risk we are happy to accept without much action. The tolerable risk level is linked to the risk tolerance level, if we go above this we get unacceptable risk. An iterative detailed risk assessment identifying how to improve is of course correct, but we should compare with the risk appetite level not the risk tolerance level.
If the design is based on the risk tolerance level there is always panic when something goes wrong. Maybe our AV update mechanism fails, this would lead to an increase in risk, if we already are at the edge because of our security design we enter immediately in an unacceptable risk situation. Where normally our defense in depth, not relying on a single control, would give us some peace of mind to get things fixed. So the risk appetite level is the better target for risk based security design.
Finally there is this attempt to combine the process safety risk and the cyber security risk into one RAM. This is possible but requires a mapping of the cyber security risk likelihood scale on the process risk likelihood scale, because they differ. They differ not necessarily at a qualitative level, but the underlying quantitative mitigated event frequency scale differs. We can not say a Medium score on the cyber security likelihood scale is equivalent with a Medium score on the process safety likelihood scale. And it is the likelihood of the cyber attack that drives the cyber related loss based risk. We have to compare this with the process safety related loss based risk to determine the bigger risk.
This comparison requires a mapping technique to account for the underlying differences in event frequency. When we do this correctly we can spot the increase in business risk due to cyber security breaches. But only an increase, cyber security is not reducing the original process safety risk that determined the business risk before we estimated the cyber security risk.
So a long story, maybe a dull topic for someone not daily involved in risk estimation, but a topic that needs to be addressed. Risk needs a sound mathematical foundation if we want to base our decisions on the results. If we miss this foundation we create the same difference as there is between astronomy and astrology.
For me, at this point in time, until otherwise convinced by your responses, the IEC / ISA 62443-3-2 method is astrology. It can make people happy going through the process, but lacks any foundation to justify decisions based on this happiness.
There is no relationship between my opinions and references to publications in this blog and the views of my employer in whatever capacity. This blog is written based on my personal opinion and knowledge build up over 42 years of work in this industry. Approximately half of the time working in engineering these automation systems, and half of the time implementing their networks and securing them.
This blog is about risk, more precise about a methodology to estimate risk in cyber physical systems. Additionally I discuss some of the hurdles to overcome when estimating risk. It is a method used in both small (< 2000 I/O) and large projects (> 100.000 I/O) with proven success in showing the relationship between different security design options, the cyber security hazards, and the change in residual cyber security risk.
I always thought the knowledge of risk and gambling would go hand in hand, but risk is a surprisingly “recent” discovery. While people gamble thousands of years, Blaise Pascal and Pierre de Fermat developed the risk methodology as recently as 1654. Risk is unique in the sense that it allowed mankind for the first time to make decisions based on forecasting the future using mathematics. Before the risk concept was developed, fate alone decided over the outcome. Through the concept of risk we can occasionally challenge fate.
Since the days of Pascal and De Fermat many other famous mathematicians contributed to the development of the theory around risk. But the basic principles have not changed. Risk estimation, as we use it today, was developed by Frank Knight (1921) a US economist.
Frank Knight defined some basic principles on what he called “risk identification”, I will quote these principles here and discuss them in the context of cyber security risk for cyber physical systems. All mathematical methods today estimating risk still follow these principles. There are some simple alternatives that estimate likelihood (this is generally the difficulty) of an event using some variables that influence likelihood (e.g. using parameters such as availability of information, connectivity, and management) but they never worked very accurate. I start with the simplest of all, principle 1 of the method.
PRINCIPLE 1 – Identify the trigger event
Something initiates the need for identifying risk. This can be to determine the risk of a flood, the risk of a disease, and in our case the risk of an adverse affect on a production process caused by a cyber attack. So the cyber attack on the process control and automation system is what we call the trigger event.
PRINCIPLE 2 – Identify the hazard or opportunity for uncertain gain.
This is a principal formulated in a way typical for an economist. In the world of process control and automation we focus on the hazards of a cyber attack. In OT security a hazard is generally defined as a potential source of harm to a valued asset. A source of discussion is if we define the hazard at automation system level or at process level. Ultimately we of course need the link to the production process to identify the loss event. But for an OT cyber security protection task, mitigating a malware cascading hazard is a more defined task than mitigating a too high reactor temperature hazard would be.
So for me the hazards are the potential changes in the functionality of the process control and automation functions that control the physical process. Or the absence of such a function preventing manual or automated intervention when the physical process develops process deviations. Something I call Loss of Required Performance (performance deviates from design or operations intent) or Loss of Ability to Perform (function is lost, cannot be executed or completed), using the terminology used by the asset integrity discipline.
PRINCIPLE 3 – Identify the specific harm or harms that could result from the hazard or opportunity for uncertain gain.
This is about consequence. Determining the specific harm in a risk situation must always precede an assessment of the likelihood of that harm. If we would start with analyzing the likelihood / probability, we would quickly be asking ourselves questions like “the likelihood of what?” Once the consequence is identified it is easier to identify the probability. In principal a risk analyst needs to identify a specific harm / consequence that can result from a hazard. Likewise the analyst must identify the severity or impact of the consequence. Here starts the first complexity when dealing with OT security risk. In the previous step (PRINCIPLE 2) I already discussed the reason for expressing the hazard initially at control and automation system level to have a meaningful definition I can use to define mitigation controls (Assuming that risk mitigation is the purpose of all this). So for the consequence I do the same I split the consequence of a specific attack on the control and automation system from the consequence for the physical production. When we do this we no longer have what we call a loss event. The consequence for the physical system results in a loss, like no product, or a product with bad quality, or worse perhaps equipment damage or fire and explosion, possibly injured people or casualties, etc.
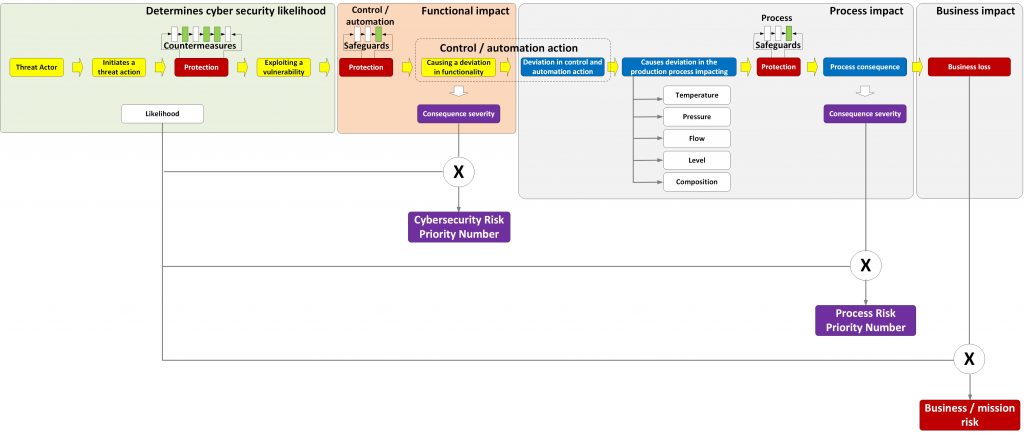
The answer for this is, what is called a risk priority number. A risk priority number is based upon what we call consequence severity (just a value on a scale). Where “true” risk would be based on an impact expressed in terms of loss. A risk priority number can be used for ranking identified hazards, they cannot be used for justifying investments. For justifying investments we need to have a risk value based upon a loss. But this step can be achieved later. Initially I am interested in selecting the security controls that contribute most to reducing the risk for the control and automation system. Convincing business management to invest in these controls is a next step. To explain this, I use the following picture.
Risk process
In the middle of the picture there is the functional impact, the deviation in the functionality of the control and automation system. This functional deviation results in a change (or absence off) the control and automation action. This change will be the cause of a deviation in the physical process. I discuss this part later.
PRINCIPLE 4 – Specify the sequence of events that is necessary for the hazard or opportunity for uncertain gain to result in the identified harm(s).
Before we can estimate the uncertainty, the likelihood / probability, we need to identify the specific sequence of events that is necessary for the hazard to result in the identified consequence. The likelihood of that precise sequence occurring will define the probability of the risk. I can use the word risk here because this likelihood is also the likelihood we need to use for the process risk, because it is the cyber-attack that causes the process deviation and the resulting consequence. (See above diagram)
The problem we face that there are many paths leading to from the hazard to the consequence. We need to identify each relevant pathway. On top of this as cyber security specialists we need to add various hurdles for the threat actors to block them reaching the end of the path, the consequence of the attack. This is where counterfactual risk analysis offers the solution. This new methodology helps us achieve this. The method analysis each possible path, based upon a repository filled with hundreds of potential event paths, and estimates the resulting likelihood of each path. Which is the next topic, PRINCIPLE 5.
PRINCIPLE 5 – Identify the most significant uncertainties in the preceding steps.
We can read the time when this statement was written in the sentence “identifying the most significant uncertainties”. In times before counterfactual analysis we needed to limit the number of paths to analyze. This can lead to and actually did lead to incidents because of missing an event path that was considered insignificant or just not identified (e.g. the Fukushima Daiichi nuclear incident). The more complex the problem, the more event paths exist, the easier we forget one. Today the estimation of likelihood and so risk progressed and is dealt with differently. Considering the complexity of the control and automation systems we have today combined with the abundance of tactics, technologies, and procedures available for the threat actor to attack, the number of paths to analyze is very high. Traditional methods can only cover a limited amount of variations, generally obvious attack scenarios we are familiar with before we start the risk analysis. The result of the traditional methods do not offer the level of detail required. Such a method would spot the hazard of malware cascading risk, the risk that malware propagates through the network. But it is not so important to learn how high malware cascading risk is, it is more important to know if it exists, which assets and channels cause it, and which security zones are affected. This information results from the event paths used in described method.
These questions require a risk estimation with a level of detail missed by the legacy methods. This is specifically very important for OT cyber security, because the number of event paths leading to deviation of a specific control and automation function is much larger than for example the number of event paths identified in process safety hazard analysis. An average sized refinery quickly leads to over 10.000 event paths to analyze.
Still we need “true” risk, risk linked to an actual loss. So far we have determined the likelihood for the event paths, we have grouped these paths to link them to hazards, so we have a likelihood for a hazard and we have a likelihood that a specific consequence can happen. Happily we can consolidate the information at this point, because we need to assign severity. Consequences (functional deviations) can be consolidated in what are called failure modes.
These failure modes result in the deviations in the production process. The plant has conducted a process safety hazop (process hazard analysis for US readers) to identify the event paths for the production system. The hazop identifies for a specific physical deviation (e.g. too high temperature, too high pressure, reverse flow, etc.) what the cause could be of this deviation and what the consequence for the production system is. These process event paths have a relationship with the failure modes / consequences identified by the first part of the risk analysis. A specific cause is can only result from a specific failure mode. We can link the cause to the failure mode and get what is called the extended event path (See diagram above) This provides us with part of the production process consequences. These consequences have an impact, an actual loss to get the mission risk required for justification of cyber security investment.
But the hazop information does not provide all possible event paths because there might be a new malicious combination of causes missed (causes can be combined by an attacker in a single attack to create a bigger impact) and we can attack the safeguards. For example we have the safety instrumented system that implements part of the countermeasures that can become a new source of risk.
The role of the SIS
To explain the role of a SIS, I use above picture to show that OT cyber security has a limited scope within overall process safety (And it would be even more limited if I used the word safety that defines personal safety, process safety, and functional safety). Several of the safeguards specified for the process safety hazard might not be a programmable electronic system and as such not a target for a cyber attack. But some such as the safety instrumented system, or a boiler management system are, so we need to consider them in our analysis and add new extended event paths where required. TRISIS / TRITON showed us SIS is a source of risk.
Since the TRISIS / TRITON cyber attack we need to consider SIS also as a source of new causes most likely not considered in a hazop. The TRISIS/TRITON attack showed us the possibility of modifying the program logic of the logic solver. This can range from simple actions like not closing shutdown valves prior to opening blow down valves and initiating a shutdown action to more complex unit or equipment specific scenarios. Though at operations level we distinguish between manual and automated emergency shutdown, for cyber security we cannot make this difference. Automated shutdown meaning the the shutdown action is triggered by a measured trip level and manual shutdown meaning that the shutdown is triggered by a push button, within the SIS program it is all the same. Once a threat actor is capable of modifying the logic, the difference between manual and automated shutdown disappears and even the highest level of ESD (ESD 0) can be initiated, shutting down the complete plant, potentially with tampered logic.
Consequences caused by cyber attacks so far
If we would look at what would be the ultimate loss resulting from a cyber attack, The “only” loss not caused by a cyber attack are so far fire, explosion, and loss of life. This is not because a cyber attack has not the capability to cause these losses, but we were primarily lucky that some attacks failed. Let’s hope we can keep it that way by adequately analyzing risk and mitigating the residual risk to a level that is acceptable / tolerable.
I don’t want to make the blog too long, but in future blogs I might jump back to some of these principles. There is more to explain on the number of risk levels, how to make risk actionable, etc. If you would unravel the text and add some more detail that I didn’t discuss the used risk method is relatively simple as the next diagram shows.
NORSOK risk model
This model is used by the Norwegian offshore industry for emergency preparedness analysis. A less complex analysis as a cyber security analysis is but that difference is primarily in how the risk picture is established. This picture is from the 2010 version (rev 3) but not that different from the rev 2 version (2001) that is freely available on the Internet. This model is also very similar to ISO 31000 shown in the next diagram.
ISO 31000 risk model
If you read how and where these models are used and how field proven the models are, also in the control and automation world, might explain a bit how surprised I was when I noticed IEC/ISA 62443-3-2 invented a whole new approach with various gaps. New is good when existing methods fail, but if methods exist that meet all requirements for a field proven methodology I think we should use these methods. Plants and engineers don’t benefit from reinventing the wheel. I am adding IEC to the ISA 62443 because last week IEC approved the standard.
I didn’t make this blog to continue the discussion I started in my previous blog, though actually there was no discussion no counter arguments were exchanged – neither did I change my opinion, but to show how risk can / was / is used in projects is important. Specifically because the group of experts doing formal risk assessments is extremely small. Most assessments end up in a short list of potential cyber security risk without identifying the sources of this risk in an accurate manner. In those situations it is difficult understand which countermeasures and safeguards are most effective to mitigate the risk. It also would not provide the level of detail necessary for creating a risk register for managing cyber security based on risk.
There is no relationship between my opinions and references to publications in this blog and the views of my employer in whatever capacity. This blog is written based on my personal opinion and knowledge build up over 42 years of work in this industry. Approximately half of the time working in engineering these automation systems, and half of the time implementing their networks and securing them.
This blog is about the in April published new ISA 99 standard, where risk and securing process control and automation systems meet. My blog is an evaluation of part ISA 62443 3-2: Security risk assessment for system design – April 2020).
I write the blog because I struggle with several of the methods applied by the standard and apparent lack of input from the field. The standard seems to ignore practices successfully used in major projects today and replaces these by in my opinion incomplete and inferior alternatives. Practices that for example are used for process safety risk analysis.
Since I executed in recent years several very large risk assessments for greenfield refineries, chemical plants and national critical industry, my technical heart just can’t ignore this. So I wanted to address these issues, because I believe the end result of this standard does not meet the quality level appropriate for an ISA 62443 standard. Very hard conclusion I know, but I will explain in the blog why this is my opinion.
When criticizing the work of others, I don’t want to do this without offering alternatives, so also in this case where I think the standard should be improved I will give alternatives. Alternatives that worked fine in the field and where applied by asset owners with a great reputation in cyber security of their plants. If I am wrong, hopefully people can show me where I am wrong and convince me the ISA 62443 3-2 can be applied.
I have been struggling with the text of this blog for 3 weeks now, I found my response too negative and not appreciating all the work done by people in the task group primarily in their spare time. So let me, before continuing with my evaluation, express my appreciation for making the standard. It is important to have a standard on this subject and it is a lot of work to make it. Having a standard document is always a good step forward, even if just for target practicing. Never the less I also have to judge the content, therefore my evaluation.
It is a lengthy blog this time, even longer than usual. But not yet a book, for a book it lacks the details on how, it has a rather quick stop and not a happy end. Perhaps one day when I am retired and free of projects I will create such a book, this time just a lengthy blog to read. People that conduct or are interested in risk assessments for OT cyber security should read it, for all others it might be too much to digest. Just a warning.
Because I can imagine that not everyone reads or has read the ISA 62443-3-2, I provide a high level overview of the various steps. I can’t copy the text 1 on 1 from the standard, that would violate ISA’s copy right. So I have to do it using my own words, which are in general a little less formal than the standard’s text. Since making standards requires a lot of word smithing, I hope I don’t deviate too much from the intentions of the original text. For the discussion I focus on those areas in the standard that surprised me most.
The standard uses 7 steps between the start of a risk assessment project to the end.
First step is to identify what the standard calls the “system under consideration”. So basically making an inventory of the systems and its components that require protection;
Second step in the proposed process is an initial cyber security risk assessment. This step I will evaluate in more detail because I believe the approach here is wrong and I question if it really is a risk assessment;
Third step is to partition the system into zones and conduits. High level I agree with this part, though I do have some minor remarks;
Fourth step asks the question if the initial risk found in the second step exceeds tolerable risk? Because of my issues with step 2, I also have issues with the content of this step;
Fifth, if the risk exceeds tolerable risk a detailed risk assessment is required. I have a number of questions here, not so much the principle itself but the detail;
In the sixth step the results are documented in the form of security requirements, plus adding some assumptions and constraints. Such a result I would call a security design / security plan. The standard doesn’t provide much detail here, so only a few comments from my side;
And finally in the seventh step there is an asset owner approval. Too logical for debate.
High level these 7 steps represent a logical approach, it are the details within these steps that inspire my blog.
Let me first focus on some theoretical points considering risk, starting with the fundamental tasks that we need to do before being able to estimate risk and than check the standard how it approaches these tasks.
In order to perform a cyber security risk analysis, it is necessary to accomplish the following fundamental tasks:
Identify the assets in need of protection;
Identify the kind of risks (or threats) that may affect the assets;
Determine the risk criteria for both the risk levels as well as the actions to perform when a risk level is reached;
Determine the probability of the identified risk occurring;
And determine the impact or effect on the plant if a given loss occurs.
Let’s evaluate the first steps of the standard against these fundamental principles.
Which assets are in need of protection for an ICS/IACS?
The ISA 62443-3-2 standard document doesn’t define the term asset, so I have to read the IEC 62443-1-1 to understand what according to IEC/ISA 62443 an asset is. According to the IEC 62443-1-1 standard the asset is defined as – in less formal words as used by the standard – an asset is a “physical or logical object” owned by a plant. The standard is here less flexible than my words because an asset is not necessarily owned by a plant, but to keep things simple I take the most common case where the plant owns the assets. The core of the definition is, an asset is a physical or a logical object. So translated into technical language, an asset is either equipment or a software function.
IEC 62443-1-1 specifies an additional requirement for an asset, it needs to have either a perceived or actual value. Both equipment and a software function have an actual value. But there is in my opinion a third asset with a perceived value that needs protection. This is the channel, the communication protocol / data flow used to exchange data between the software functions. Not exactly a tangible object but still I think I can call at minimum an asset if I consider it a data flow using a specific protocol.
Protection of a channel is important, cyber security risk is for a large part linked to exposure of a vulnerability. Vulnerable channels, for example a data flow using the Modbus TCP / IP protocol (this protocol has several vulnerabilities that can be exploited), induce risk. So for me the system under consideration is:
The physical equipment (e.g. computer equipment, network equipment, and embedded devices);
The functions (software, for example SIS (Safety Instrumented System) and BPCS (Basic process Control System). But many more in today’s systems);
And the channels (the data flows, e.g. Modbus TCP/IP or a vendor proprietary protocol).
The ISA 62443-3-2 standard document doesn’t mention these three as explicitly as I do, but the text is also not in conflict with my definition of assets in need of protection. So no discussion here from my side. Before we can assess OT cyber security risk we need to have a good overview of these “assets”, the scope of the risk assessment.
The second step is an initial risk assessment, here I start to have issues. The standard asks us to identify the “worst case unmitigated cyber security risk” that could result from a cyber attack. It suggests to express this in terms of impact to health, safety, production loss, product quality, etc. This is what I call mission risk or business risk. The four primary factors that induce this risk are:
Process operations;
Process safety;
Asset integrity;
Cyber security;
Without process safety many accidents can occur, but even a plant in a perfect “safe” state can impact product quality and production loss. So we need to include process operations as well. Failing assets can also lead to production loss, or even impact to health. Asset integrity is the discipline that evaluates the maintenance schedules and required maintenance activities. Potential failures made by this discipline also add to the business / mission risk. And then we have cyber security. Cyber security can alter or halt the functionality of the various automation functions, and can alter data integrity, and even compromise the confidentiality of a plant’s intellectual property. All above are elements that can result in a loss and so induce mission risk. But cyber security can do more than this, it can make implemented safety integrity functions (SIF) for process safety ineffective, it can misuse the SIF logic to cause loss. Additionally cyber security can also cause excessive wear of process equipment not accounted for by asset integrity. Cyber security is an element that influences all.
For determining initial risk, the approach taken by the standard is to use the process hazard analysis (PHA) results as input for identifying the worst case impacts. And additional to this the standard requests us to consider information from the sector, governments, and other sources to get information on the threats.
I have several issues here. The first, can we have risk without likelihood? The PHA can define a likelihood in the PHA sheet, but this likelihood has no relationship with the likelihood of facing a cyber attack. So using it would would not result in cyber security risk.
Another point is that if we consider the impact, the PHA would offer us the worst case impact based upon the various deviations analyzed from a process safety perspective. But this is not necessarily the worse case impact from a business perspective.
See the definition for process safety: “The objective of process safety management is to ensure that potential hazards are identified and mitigation measures are in place to prevent unwanted release of energy or hazardous chemicals into locations that could expose employees and others to serious harm.”
The PHA would not necessarily analyze the impact of product quality for the company. Pharmaceutical business and food and beverage business can face major impact if its products would have a quality issue, while their production process can be relatively safe compared to a chemical plant.
If we would take the PHA as input, will it address the “worst case impact”? PHA will certainly be complete for the analysis of the process deviations (the structured approach of the PHA process enforces this) and complete for the influence of these deviations on process safety, so should also be complete for the consequences too if all process deviations are examined.
But the PHA might not be complete when it comes to the possible causes, because PHA generally doesn’t consider malicious intent. So there might be additional causes that are not considered as possible by the PHA.
Causes are very important because these result from functional deviations as result of the cyber attack. It is the link between the functional deviation and its physical effect on the production process that causes the process deviations and its consequence / impact.
If it is not guaranteed that the PHA covers all potential causes, the reverse path from “worst case impact” in the PHA to the “cyber security functional deviation” that causes a process deviation is interrupted. This interruption doesn’t only prevent us from getting a likelihood value, but also prevents us from identifying all mitigation options. Walking the event path in the reverse direction is not going to bring us the likelihood of the process deviation happening as result of a cyber attack, so we don’t have risk.
If I follow the methodology of analyzing risk using event paths, I have the following event path:
A threat actor executes a threat action to exploit a vulnerability resulting in some desired consequence, this consequence is a functional deviation causing a process deviation with some process consequence.
The process consequence has a specific impact for the business / mission, such as production loss, potential casualties, a legal violation, etc. This impact (expressed as loss) creates business risk.
The picture shows that the risk path between a cyber security breach resulting in mission impact requires several steps. The standard jumps right to the end (business impact) not considering intermediate consequences, by doing this the standard ignores options to reduce risk. But more on this later.
The path toward mission risk
So as an example of an event path: A nation sponsored organization (threat actor) gains unauthorized access into an ICS (threat action) by capturing the access credentials of an employee without two factor authentication (vulnerability), modifying the range of a tank level instrument (functional deviation), causing a too high level in the tank (process deviation) with as potential consequence overfilling the tank (process consequence) resulting in a loss of containment of a potentially flammable fluid causing toxic vapors requiring an evacuation resulting in potentially multiple casualties and an approximate $500.000 production and cleaning cost loss (business impact).
An extended event path in more detail
The likelihood that this event path, scenario, happens as result of a cyber attack is determined by the likelihood of the cyber security failure. The PHA might have considered a similar process deviation (High level in the tank) during the analysis, perhaps with as cause mentioned a failed level transmitter, and reached the same process consequence as potential loss of containment. All very simplified, don’t worry we do apply additional controls.
But the likelihood assigned to this process safety hazard would have been derived from a LOPA (Layers Of Protection Analysis) assignment based on an initiating frequency assignment and an IPL (Independent Protection Layer) reduction factor and MTBF factors of the instrument to estimate a SIL required for the safeguard. There is no relationship between the likelihood of the process deviation in the PHA and the cyber security likelihood.
Important is to realize that not all risk estimates are necessarily linked to a loss. Ideally this is so, because the loss justifies the investment in mitigation. But in many cases we can use what are called risk priority numbers, a risk score based on likelihood and severity for ranking purposes. A risk priority number is often enough for us to decide on mitigation and prioritizing mitigation. For design we only need business risk if the investment needs to be justified. The risk priority numbers already show the most important risk from a technical perspective.
However my conclusion is that the standard is not approaching the initial risk assessment by estimating cyber security risk, it seems to focus on two other aspects:
What is the worst impact (Expressed as a loss);
and what does the threat landscape look like.
Neither of them providing a risk value. I fully understand the limitation, because so early in a project there is not enough information available to estimate risk at a level of detail showed above.
So in my opinion an alternative approach is required, and such alternatives exist. Better they have been widely applied in the industry in recent years, but for some reason are ignored by the task group and replaced by something questionable in my opinion.
So how did projects resolve the lack of information and still get important information for understanding the business impact and threats to protect against? Following activities were performed in projects:
Create a threat profile by conducting a threat assessment;
Conduct a criticality assessment / business impact analysis.
What is a threat profile? The objective of a threat profile is to:
Identify the threat actors to be considered;
Identify and prioritize cyber security risk;
Align information security risk and OT security risk strategies within the company.
Identifying and prioritizing cyber security risk is done by studying the threat landscape based upon various reliable sources, such as information from a local CERT, MITRE, FIRST, ISF, and various commercial sources. These organizations show the developments in the threat landscape explaining the activities of threat actors and what they do.
Threat actors are identified and their relevance for the company can be rated based on criteria such as: intent, origin, history, motivation, capability, focus. Based on these criteria a threat strength and likelihood can be estimated. Various methods have been developed, for example the method developed by ISF is frequently used.
Based on the information on threat actors and their methods and their focus, a threat heat map is created. So the asset owner can decide on what the priorities are. This is an essential input for anyone responsible for the cyber security of a plant, but also important information for a cyber security risk assessment. Threat actors considered as relevant, play a major role in the required risk reduction for an appropriate protection level. If we don’t consider the threat actor we will quickly over-spend or under-spend on risk mitigation.
In the ISA 62443-3-2 context, the target security level (SL-T) is used as the link toward the threat actor. Because ISA security levels link to motivation, capability, and resources of the threat actor, a security level also identifies a threat actor. The idea is to identify a target security level for each security zone and use this to define the technical controls for the assets in the zone, specified as capability security levels (SL-C) in the IEC 62443-3-3. The IEC 62443-3-3 provides the security requirements that the security zones and conduits must meet to offer the required level of protection.
The ISA 62443-3-2 document does not explain how this SL-T is defined. But if the path is to have an SL-T per security zone, then we need to estimate zone risk. Zone risk is something very different from asset risk or threat based risk. The ANSSI standard provides a method to determine zone risk and uses the result to determine a security class (A,B, C) something similar as the ISA security levels.
I would expect a standard document on security risk assessment to explain the zone risk process, but the standard doesn’t. Because the methodology actually seems to continue with an asset based risk approach I assume the idea is that the asset with the highest risk level in a zone determines the overall zone risk level. This is a valid approach but more time consuming than the ANSSI approach.
For a standard / compliance based security strategy a zone risk approach would have been sufficient. The use of SL-T and SL-C and reference to IEC 62443-3-3 seems to suggest a standard’s / compliance based security approach.
How about the other method in use, the criticality assessment. What does it offer? The criticality assessment helps to establish the importance of each functional unit and business process as it relates to the production process. Illustrating which functions need to be recovered, how fast do they need to be recovered and what their overall importance is from both a business perspective as well as from a cyber security perspective. Which are two totally different perspectives. An instrument asset management system might have a low importance from a business point of view, but because of its connectivity to all field instrumentation it can be considered an important system to protect from a cyber security perspective.
So executing a criticality assessment as second step provides the criticality of the functions (importance and impact do correlate), and it provides us with information on the recovery timing.
OT cyber security risk should not exclusively focus on the identification of the risk related to the threats and how to mitigate it. Residual business risk is not only influenced by preventative and detective controls but also by the recovery potential and speed, because the speed of recovery determines business continuity and lack of business continuity can be translated to loss.
ISA 62443-3-2 doesn’t address the recovery aspect in any way. As the risk assessment is used to define the security requirements, we can not ignore recovery requirements. NIST CSF does acknowledge recovery as an important security aspect, I don’t understand why the ISA 62443-3-2 task group ignored recovery requirements as part of their design risk assessment.
It is important to know the recovery point objective (RPO), recovery time objective (RTO) and maximum tolerable downtime (MTD) for the ICS / IACS. Designing recovery for a potential cyber threat, for example a ransomware infection, differs quite a lot from data recovery from an equipment failure.
In a plant with its upstream and down stream dependencies and storage limitations, these parameters are important information for a security design. See below diagram for the steps in a typical cyber incident. Depending on their detailed procedures, these steps can be time consuming.
Response and recovery
The criticality assessment investigates Loss of Ability to Perform over a time span, for example how do we judge criticality after 4 hours, 8 hours, a day, a week, etc… This allows us to consider the dependencies of upstream and downstream processes, and storage capacity. But apart from looking at loss of ability to perform, loss of required performance and loss on confidentiality are also evaluated in a cyber security related criticality assessment. Specifically the loss of required performance links to the “worst impact” looked for by the ISA 62443-3-2.
We also need to consider recovery point objectives (RPO) and understand how the plant wants to recover, are we going to use the most recent controller checkpoint or are there requirements for a controller checkpoint that brings the control loops into an known start-up state.
We need to understand the requirements for the recovery time objective (RTO), this differs for cyber security compared to a “regular” failure. For cyber security we need to include the time taken by the incident response tasks, such as containment and eradication of the potential malware or intruder.
It makes a big difference in time if our recovery strategy opts for restoring a back-up to new hard drives, or if we decide to format the hard drives before we restore (and what type of reformatting would be required). Other choices to consider are back-up restore over the network from one or more central locations, or restore directly at computer level using USB drives. All of this and more has time and cost impact that the security design needs to take into account.
The role of the criticality assessment is much bigger than discussed here, but it is an essential exercise for the security design and as such for the risk assessment that also requires us to assess consequence severity. Consequence severity analysis is actually just an extension of the criticality analysis.
Another important aspect of criticality analysis is that it includes ICS / IACS functions not being related to any of the hazards identified by the PHA. For our security design we need to include all IACS systems, not limit our selves to systems at Purdue reference model level 0, 1 and 2.
A modern IACS has many functions, all ignored by the ISA 62443-3-2 standard if we start at the PHA. IACS includes not only the systems at the Purdue level 0, 1 and 2, (systems typically responsible for the PHA related hazards) but also the systems at level 3. Systems that can still be of vital importance for the plant. The methodology of the standard seems to ignore these.
Another role for the criticality assessment is directly related to the risk assessment. An important question in a large environment is do we assess risk per sub-system or for the whole system. Doing it for the whole system (IACS) with all its sub-systems (BPCS, SIS, MMS, …) and a large variation of different consequences and cross relations, or do we assess risk per function and consolidate these results for comparison in for example a risk assessment matrix.
The standard seems to go for the first approach, which in my opinion (based upon risk assessments for large installations) is a far too difficult and complex exercise. If we keep the analysis very general (and as a result superficial, often at an informal gut-feeling-risk level) it is probably possible, but the results often become very subjective and we miss out on the benefits that other methods offer.
As the base for a security design that is resilient to targeted attacks and its subsequent risk based security management (this would require a risk register) of the complete ICS/IACS, I believe it is an impossible task. All results of a risk assessment need to meet the sensitivity test, and the results need to be discriminitive enough to have value. This requires that methods applied, prevent any subjective inputs that steer the results into a specific direction.
If we select a risk assessment approach per function to allow for more detail, we have to take the difference in criticality of the function into account when comparing risk of different functions. This is of minor importance when we compare risk results from SIS (Safety Instrumented System) or BPCS (Basic Process Control System), because both are of vital importance in a criticality analysis. But we will already see differences in results when we would compare BPCS with MMS (Machine Monitoring System), IAMS (Instrument Asset Management System) or DAHS (Data Acquisition Historian System).
As I already mentioned in my previous blog, risk assessment methodologies have evolved and the method suggested by ISA 62443-3-2 seems to drive toward an approach that can’t handle the challenges of today’s IACS. Certainly not for the targeted attacks where threat actors with “IACS specific skills” ( SL 3, SL 4). To properly execute a risk assessment in an OT environment requires knowledge on the different methods for assessing risk, their strong and weak points, and above all a clear objective for the selected method.
So to conclude my assessment of the second step of the ISA 62443-3-2 process, “Initial risk assessment”, I feel the task group missed too much in this step. The result offers too little, is incomplete and actually providing very little useful information for the next steps, among which the “security zone partitioning”.
Now lets look at the zone partitioning step, to see how the standard and my field experience aligns here.
First of all what is the importance of security zone partitioning with regard to security risk assessment?
If we want to use zone risk we need to know the boundaries of the security zone;
For asset risk and threat based risk we need to know the exposure of the asset / channel and connectivity between zones over conduits is an important factor.
So it is an important step in a security risk assessment, even for none security standard based strategies. Let’s start with the overview of what project steps the standard specifies:
Establish zones and conduits;
Separate business and ICS/IACS assets;
Separate safety related assets;
Separate devices that are temporarily connected;
Separate wireless devices;
Separate devices connected via external networks.
Looks like a logical list to consider when creating security zones, but certainly not a complete list. The list seems to be driven by exposure, which is good. But there are other sources of exposure. We can have 24×7 manned and unmanned locations, important for yes / no a session lock of operator stations, so a security characteristic. We have to consider the strength of the zone boundary, is it a physical perimeter (e.g. network cable connected to the port of a firewall), a logical perimeter (e.g. a virtual LAN), or do we have a software defined perimeter (e.g. a hypervisor that separates virtual machines on virtual network segments).
The standard, and as far as I am aware none of the other ISA standards, consider virtualization. This is a surprise for me because virtualization seems to be core for the majority of greenfield projects, and even as part of brown field upgrade projects virtualization is a frequent choice today. Considering that the standard is issued April 2020, and ISA has a policy to refresh standards every 5 years, this is a major gap because software zone perimeters for security zones is an important topic.
Considering that virtualization is a technology used in many new installations, and considering the changes that technology like APL and IIoT are bringing us. Not addressing these technologies in a risk based design document that discusses zone partitioning makes the standard almost obsolete in the year it is issued.
Perhaps a very hard verdict, but a verdict based on my personal experience where 4 out of 5 large greenfield projects were based on virtualized systems a subject that should have been covered. Ignoring virtualization for zone partitioning is a major gap in 2020 and the years to come.
There is a whole new “world” today of virtual machine hosts, virtual machines, hardware clusters, and software defined perimeters. And this has nothing to do with the world of private clouds or Internet based clouds, virtualization is proven technology for at least 5+ years now, conquering ICS/IACS space with increasing speed. It should not have been missed.
The 62443-3-2 standard is not very specific with regard to the other subjects in this step, so little reason for me to criticize the remainder of the text. If I have to add a point, then I might say that the paragraph on separating safety and non-safety related assets is very thin. I would have expected a bit more in April 2020, plenty of unanswered design questions for this topic.
The next step the standard asks us to do is “risk comparison“, we have to compare initial risk (step 2) with residual risk, the risk after the zone partitioning step. There is the “little” issue that neither in the initial risk assessment step, nor in the zone partitioning step we estimate risk. Nor do we establish anywhere risk criteria, important information when we want to compare risk.
Zone partitioning does change the risk, we influence exposure through connectivity, but there is no risk estimated in the partitioning step. Perhaps the idea is to take the asset with the highest risk in the zone and use this for the SL-T / SL-C and identify missing security requirements, but this is not specified and would be an iterative process because also asset risk depends among others on exposure from connectivity.
I had expected something in the partitioning task that would estimate / identify zone risk and assign the zone a target security level using some transformation matrix from risk to security level. The standard doesn’t explain this process, it doesn’t seem to be an activity of the zone partitioning task, it doesn’t refer to another standard document for solving it. Which is an omission in my opinion.
But ok no problem, if we can’t accept the residual risk we are going to do the next step, the detailed risk assessment and keep iterating till we accept the residual risk. So perhaps I must read this more as a first step in an evaluation loop. Doesn’t take away that if I decide first time I am happy with the residual risk, I will have nothing else than what the initial risk assessment produced, and this was not cyber security risk.
The fifth step is the detailed risk assessment. Let’s see what we need to do:
Identify cyber security threats;
Identify vulnerabilities;
Determine consequences and impact;
Determine unmitigated likelihood;
Determine unmitigated cyber security risk;
Determine security level target to link to the IEC 62443-3-3 standard.
If the unmitigated risk exceeds tolerable risk we need to continue with mitigation. Following steps are defined:
We need to identify and evaluate existing countermeasures;
We are asked to reevaluate the likelihood based on these existing countermeasures;
Determine the new residual risk;
Compare residual risk against tolerable risk and reiterate the cycle if the residual risk is still too high;
If all residual risk is below the tolerable risk, we document the results in the risk assessment report.
To do all of the above we need to have risk criteria, these are not mentioned in the standard neither is mentioned what criteria there are. The standard seems to adopt the three risk levels often used for process safety: acceptable risk, tolerable risk, and unacceptable risk.
Unfortunately this is too simple for cyber security risk. When process safety risk is unacceptable, an accepted policy is too stop and fix it before continuing. For tolerable risk there would be a plan in place on how to improve it when possible.
Cyber security doesn’t work that way, I have seen many high cyber security risks, but only in a few cases noted that plant managers were willing to accept a loss (production stop) to fix it. An example where loss because of security risk was accepted was when Aramco and 2 weeks later Qatar gas were attacked by the Shamoon malware. At that time the regional governments instructed the plants to disconnect the ICS/IACS from their corporate network, this induces extra cost. We have seen similar decisions caused by ransomware infections, plants pro-actively stopping production to prevent an infection propagating.
Cyber security culture differs from process safety culture, this translates into risk criteria and the action-ability of risk. The less risk levels, the more critical the decision. As result, plants seem to have a preference for 5 or 6 risk levels. This allows them a bit more flexibility.
Tolerable risk is the “area” between risk appetite and risk tolerance. Risk appetite being the level we can continue production without actively pursuing further risk reduction, and risk tolerance being the limit above which we require immediate action. Risk criteria are important, in the annex ISA 62443-3-2 provides some examples in risk matrices. A proper discussion on risk criteria is missing. Likelihood levels, severity levels, impact levels, importance levels all need to be defined. It is important that if we say this is a high risk, all involved understand what this means. Also actions need to be defined for a risk level, risk needs to result into some action if it exceeds a level.
The standard limits itself to business risk, impact expressed as a loss. Business risk is great to justify investment but does very little for identifying the most important mitigation opportunities because it is a worst case risk. It is like saying if I am walking in a thunderstorm I can die from being struck by lightning, so I no longer need to analyze the risk using a zebra to cross the road.
Another point of criticism I have is why only risk reduction based on likelihood reduction is considered. The standard seems to ignore addressing opportunities on the impact side for taking away consequences? Reduction on the consequence side has proved to be far more effective. In the methodology chosen by the standard this is not possible because the only impact / consequence recognized is the ultimate business impact. The consequences leading to this impact, the functional deviation in IACS functions, are not considered.
Risk event path
The three step process described in above block diagram of risk and shown in more detail in my previous blog as the “event path” doesn’t exist for the ISA adopted method. Though it are the countermeasures and safeguards we use to reduce the cyber security risk.
For example there are many plants that do not allow the use of the Modbus TCP/IP protocol for switching critical process functions using PLCs that depend on Modbus communication. If such an action is required they hardwire the connection to prevent being vulnerable for various Modbus TCP/IP message injection and modification attacks. This is a safeguard taking a way a very critical consequence such as an unauthorized start or stop of a motor, compressor or other by injecting a Modbus message.
Another point we are asked to do is to determine the security level target (SL-T). Well assuming there is some transformation matrix converting risk into security level (not in the ISA 62443-3-2) we can do this, but how?
It is a repeating issue, the standard doesn’t explain if I need to use zone risk like ANSSI does, or determine zone risk as the asset with the maximum risk in a zone. And when I have risk what would be the SL-T?
Once we have an SL-T we can compare this with the security level capability (SL-C) to get the security requirements from the IEC 62443-3-3. ISA 62443-3-2 seems to be restrict to the standard based security strategy. A good point to start but not a solution for critical infrastructure.
ISA 62443 3-2 is a standards-based security strategy.
Another surprise I have is the focus on the unmitigated risk, why not include the existing countermeasures immediately? Why are we addressing risk mitigation exclusively by addressing likelihood. Where do we include the assets to protect (equipment, function, channel)? I think I know the answer, the risk methodology adopted doesn’t support it. The task group either didn’t investigate the various risk estimation methodologies available or worked for some reason toward applying a methodology that is not capable of estimating risk for multiple countermeasures / safeguards. Which is strange choice because in process safety this methodology is successfully applied through LOPA.
So how to summarize this pile of criticism? First of all I want to say that this is the standard document I criticize the most, maybe because it is the subject that comes closest to my work. There are always small points where opinions can deviate, but in this case I have the feeling the standard doesn’t offer what it should bring, it seems to struggle with the very concept of risk analysis. Which is amazing because of the progress made by both science and asset owners in recent years.
Because risk is such an essential concept for cyber security I am disappointed in the result, despite all the editing of this blog and the many versions that were deleted I think the blog still shows this disappointment.
It is my feeling that the task group didn’t investigate the available risk methodologies sufficiently, didn’t study the subject of risk analysis, and they didn’t seem to compare results of the different methods. They aimed for one method and wrote the standard around it. That is a pity because it will take another 5 years before we see an update and 5 years in cyber security are an eternity.
There is no relationship between my opinions and references to publications in this blog and the views of my employer in whatever capacity. This blog is written based on my personal opinion and knowledge build up over 42 years of work in this industry. Approximately half of the time working in engineering these automation systems, and half of the time implementing their networks and securing them.
This week’s blog discusses what a Hazard and Operability study (HAZOP) is and some of the challenges (and benefits) it offers when applying the method for OT cyber security risk. I discuss the different methods available, and introduce the concept of counterfactual hazard identification and risk analysis. I will also explain what all of this has to do with the title of the blog, and I will introduce “stage-zero-thinking”, something often ignored but crucial for both assessing risk and protecting Industrial Control Systems (ICS).
What inspired me this week? Well one reason – a response from John Cusimano on last week’s Wake-up call blog.
John’s comment: “I firmly disagree with your statement that ICS cybersecurity risk cannot be assessed in a workshop setting and your approach is to “work with tooling to capture all the possibilities, we categorize consequences and failure modes to assign them a trustworthy severity value meeting the risk criteria of the plant.”. So, you mean to say that you can write software to solve a problem that is “impossible” for people to solve. Hm. Computers can do things faster, true. But generally speaking, you need to program them to do what you want. A well facilitated workshop integrates the knowledge of multiple people, with different skills, backgrounds and experience. Sure, you could write software to document and codify some of their knowledge but, today, you can’t write a program to “think” through these complex topics anymore that you could write a program to author your blogs.”
Not that I disagree with the core of John’s statement, but I do disagree with the role of the computer in risk assessment. LinkedIn is a nice medium, but responses always are a bit incomplete, and briefness isn’t one of my talents. So a blog is the more appropriate place to explain some of the points raised. Why suddenly an abstract? Well this was an idea of a UK blog fan.
I write my blogs not for a specific public, though because of the content, my readers most likely are involved in securing ICS. I don’t think the “general public” public can digest my story easily, so they probably quickly look for other information when my blog lands in their window or they read it till the end and think what was this all about. But there is a space between the OT cyber security specialist, and the general public. I call this space “sales” technical guys but at a distance, and with the thought in mind that “if you know the art of being happy with simple things, then you know the art of having maximum happiness with minimum effort”, I facilitate the members of this space by offering a content filter rule – the abstract.
The process safety HAZOP or Process Hazard Analysis as non-Europeans call the method, was a British invention in the mid-sixties of the previous century. The method accomplished a terrific breakthrough in process safety and made the manufacturing industry a much safer place to work.
How does the method work? To explain this I need to explain some of the terminology I use. A production process, for example a refinery process, is designed creating successive steps of detail. We start with what is called a block flow diagram (BFD), each block represents a single piece of equipment or a complete stage in the process. Block diagrams are useful for showing simple processes or high level descriptions of complex processes.
For complex processes the BFD use is limited to showing the overall process, broken down into its principal stages. Examples of blocks are a furnace, a cooler, a compressor, or a distillation column. When we add more detail on how these blocks connect, the diagram is called a process flow diagram. A process flow diagram (PFD) shows the various product flows in the production process, an example of a PFD is the next text book diagram of a nitric acid process.
Process Flow Diagram. (Source Chemical Engineering Design)
We can see the various blocks in a standardized format. The numbers in the diagram indicate the flows, these are specified in more detail in a separate table for composition, temperature, pressure, … We can group elements in what we call process units, logical groups of equipment that accomplish together a specific process stage. But what we are missing here is the process automation part, what do we measure, how do we control the flow, how do we control pressure? This type of information is documented in what is called a piping and instrument diagram (P&ID).
The P&ID shows the equipment numbers, valves, the line numbers of the pipes, the control loops and instruments with an identification number, pumps, etc. Just like for PFDs we also used use standard symbols in P&IDs to describe what it is, to show the difference between a control valve and a safety valve using different symbols. The symbols for the different types of valves already covers more than a page. If we look at the P&ID of the nitric acid process and zoom into the vaporizer unit we see that more detail is added. Still it is a simplified diagram because the equipment numbers and tag names are removed, alarms have been removed, and there are no safety controls in the diagram.
The vaporizer part of the P&ID (Source Chemical Engineering Design)
On the left of the picture we see a flow loop indicated with FIC (the F from flow, the I from indicator, and the C from control), on the right we see a level control loop indicated with (LIC). We can see which transmitters are used to measure the flow (FT) or the level (LT). We can see the that control valves are used (the rounded top of the symbol). Though above is an incomplete diagram, it shows very well the various elements of a vaporizer unit.
Similar diagrams, different symbols and of course a totally different process, exist for power.
When we engineer a production / automation process P&IDs are always created to describe every element in the automation process. When starting an engineering job in the industry, one of the first things to learn is this “alphabet” of P&ID symbols the communication language for documenting the relation between the automation system (the ICS) and the physical system. For example the FIC loop will be configured in a process controller, there will be “tagnames” assigned to each loop, graphic displays created so the process operator can track what is going on and intervene when needed. Control loops are not configured in a PLC, process controllers and PLCs are different functions and have a different role in an automation process.
So far the introduction for discussing the HAZOP / PHA process. The idea behind a HAZOP is that we want to investigate: What can go wrong; What the consequence of this would be for the production process; And how we can enforce that if it goes wrong the system is “moved” to a safe state (using a safeguard).
There are various analysis methods available, I discuss the classical method because this is similar to what is called a computer HAZOP and like the method John suggests. The one that is really different, counterfactual analysis, and is especially used for complex problems like OT cyber security for ICS I discuss last.
A process safety HAZOP is conducted in a series of workshop sessions with participation of subject matter experts of different disciplines (Operations, safety, maintenance, automation, ..) and led by a HAZOP “leader”, someone not necessarily a subject matter expert on the production process but a specialist in the HAZOP process it self. The results of HAZOPs are as good as the participants and even with very knowledgeable subject matter experts and an inexperienced HAZOP leader results might be bad. Experience is a key factor in the success of a HAZOP.
The inputs for the HAZOP sessions are the PFDs and P&IDs. P&IDs typically represent a process unit but if this is not the case, the HAZOP team selects a part of the P&ID to zoom into. HAZOP discussions focus on process units, equipment and control elements that perform a specific task in the process. Our vaporizer could be a very small unit with a P&ID. The HAZOP team could analyze the various failure modes of the feed flow using what are called “guide words” to guide the analysis in the topics to analyze. Guide words are just a list of topics used to check a specific condition / state. For example there is a guide word High, and another Low, or No, and Reverse. This triggers the HAZOP team to investigate if it is possible to have No flow, is it possible to have High flow, Low flow, Reverse flow, etc. If the team decides that it is possible to have this condition, for example No Flow, they write down the possible causes that can create the condition. What can cause No flow, well perhaps a cause is a valve failure or a pump failure.
When we have the cause we also need to determine the consequence of this “failure mode”, what happens if we have No flow or Reverse flow. If the consequence is not important we can analyze the next, otherwise we need to decide what to do if we have No flow. We certainly can’t keep heating our vaporizer, so if there is no flow so we need to do something (the safeguard).
Perhaps the team decides on creating a safety instrumented function (SIF) that is activated on a low flow value and shuts down the heating of the vaporizer. These are the safeguards, initially high level specified in the process safety sheet but later in the design process detailed. A safeguard can be executed by a safety instrumented system (SIS) using a SIF and are implemented as mechanical devices. Often multiple layers of protection exist, the SIS being only one of them. A cyber security attack can impact the SIS function (modify it, disable it, initiate it), but this is something else as impacting process safety. Process safety typically doesn’t depend on a single protection layer.
Process safety HAZOPs are a long, tedious, and costly process that can take several months to complete for a new plant. And of course if not done in a very disciplined and focused manner, errors can be made. Whenever changes are made in the production process the results need to be reviewed for their process safety impact. For estimating risk a popular method is to use Layers Of Protection Analysis (LOPA). With the LOPA technique, a semi-quantitative method, we can analyze the safeguards and causes and get a likelihood value. I discuss the steps later in the blog when applied for cyber security risk.
Important to understand is that the HAZOP process doesn’t take any form of malicious intent into account, the initiating events (causes) happen accidentally not intentionally. The HAZOP team might investigate what to do when a specific valve fails closed with as consequence No Flow, but will not investigate the possibility that a selected combination of valves fail simultaneously. A combination of malicious failures that might create a whole new scenario not accounted for.
A cyber threat actor (attacker) might have a specific preference on how the valves need to fail to achieve his objective and the threat actor can make them fail as part of the attack. Apart from the cause being initiated by the threat actor, also the safeguards can be manipulated. Perhaps safeguards defined in the form of safety instrumented functions (SIF) executed by a SIS or interlocks and permissives configured in the basic process control system (BPCS). Once the independence of SIS and BPCS is lost the threat actor has many dangerous options available. There are multiple failure scenarios that can be used in a cyber attack that are not considered in the analysis process of the process safety HAZOP. Therefore the need for a separate cyber security HAZOP to detect this gap and address it. But before I discuss the cyber security HAZOP, I will briefly discuss what is called the “Computer HAZOP” and introduce the concept of Stage-Zero-Thinking.
A Computer HAZOP investigates the various failure modes of the ICS components. It looks at the power distribution, operability, processing failures, network, fire, and sometimes at a high level security (can be both physical as well as cyber security). It might consider malware, excessive network traffic, a security breach. Generally very high level, very few details, incomplete. All of this is done using the same method as used for the process safety HAZOP, but the guide words are changed. In a computer HAZOP we work now with guide words such: “Fire”, Power distribution” “Malware infection”, etc. But still document the cause, consequence, and consider safeguards in a similar manner as for the process safety HAZOP. Consequences are specified at high level such as loss of view, loss of control, loss of communications, etc.
At a level we can judge their overall severity but not link it to detailed consequences for the production process. Cyber security analysis at this level would not have foreseen such advanced attack scenarios as used in the Stuxnet attack, it remains at a higher level of attack scenarios. The process operator at the Natanz facility also experienced a “Loss of View”, a very specific one the loss of accurate process data for some very specific process loops. Cyber security attacks can be very granular, requiring more detail than consequences as “Loss of View” and “Loss of Control” offer, for spotting the weak link in the chain and fix it. If we look in detail how an operator HMI function works we soon end up with quite a number of scenarios. The path between the finger tips of an operator typing a new setpoint and the resulting change of the control valve position is a long one with several opportunities to exploit for a threat actor. But while threat modelling the design of the controller during its development many of these “opportunities” have been addressed.
The more complex the number of scenarios we need to analyze the less appropriate the execution of the HAZOP method in the traditional way is because of the time it takes and because of the dependence on subject matter experts. Even the best cyber security subject matter specialists can miss scenarios when it is complex, or don’t know about these scenarios because they don’t have the knowledge of the internal workings of the functions. But before looking at a different, computer supported method, first an introduction of “stage-zero-thinking”.
Stage-zero refers to the ICS kill chain I discussed in an earlier blog where I tried to challenge if an ICS kill chain always has two stages. A stage 1 where the threat actor collects the specific data he needs for preparing an attack on the site’s physical system, and a second stage where actual attack is executed. We have seen these stages in the Trisis / Triton attack , where the threat actors attacked the plant two years before the actual attempt collect information in order to attack a safety controller for modifying the SIS application logic.
What is missing in all descriptions of TRISIS attack so far is stage 0, the stage where the threat actor made his plans to cause a specific impact on the chemical plant. Though the “new” application logic created by the threat actors must be known (part of the malware), it is nowhere discussed what the differences were between the malicious application logic and the existing application logic. This is a missed opportunity because we can learn very much from understanding rational behind the attackers objective. Generally objectives can be reached over multiple paths, fixing the software in the Triconex safety controller might have blocked one path but it is far from certain if all paths leading to the objective are blocked.
For Stuxnet we know the objective thanks to the extensive analysis of Ralph Langner, the objective was manipulation of the centrifuge speed to cause excessive wear of the bearings. It is important to understand the failure mode (functional deviation) used because this helps us to detect it or prevent it. For the attack on the Ukraine power grid, the objective was clear … causing a power outage .. the functional deviation was partially unauthorized operation of the breaker switches and partially the corruption of protocol converter firmware to prevent the operator to remotely correct the action. This knowledge provides us with several options to improve the defense. Another attack, the attack on the German Steel mill the actual method used is not known. They gained access using a phishing attack but in what way the attacker caused the uncontrolled shutdown is never published. The objective is clear but the path to it not, so we are missing potential ways to prevent it in future. Just preventing unauthorized access is only blocking one path, it might still be possible to use malware to do the same. In risk analysis we call this the event path, the longer we oversee this event path the stronger our defense can be.
Attacks on cyber physical systems have a specific objective, some are very simple (like the ransomware objective) some are more complex to achieve like the Stuxnet objective or in power the Aurora objective. Stage-zero-thinking is understanding which functional deviations in the ICS are required to cause the intended loss on the physical side. The threat actor starts at the end of the attack and plans an event path in the reverse direction. For a proper defense the blue team, the defenders, needs to think like the red team. If they don’t they will always be reactive and often too late.
The first consideration of the Stuxnet threat actor team must have been how to impact the uranium enrichment plant to stop doing what ever they were doing. Since this was a nation state level attack there were of course kinetic options, but they selected the cyber option with all consequences for the threat landscape of today. Next they must have been studying the production process and puzzling how to sabotage it. In the end they decided that the centrifuges were an attractive target, time consuming to replace and effectively reducing the plant’s capacity. Than they must have considered the different ways to do this, and decided on making changes in the frequency converter to cause the speed variations responsible for the wear of the bearings. Starting at the frequency converter they must have worked their way back toward how to modify the PLC code, how to hide the resulting speed variations from the process operator, etc, etc. A chain of events on this long event path.
in the scenario I discussed in my Trisis blog I created the hypothetical damage through modifying a compressor shutdown function and subsequently initiating a shutdown causing a pressure surge that would damage the compressor. Others suggested the objective was a combined attack on the control function and process safety function. All possible scenarios, the answer is in the SIS program logic not revealed. So no lesson learned to improve our protection.
My point here is that when analyzing attacks on cyber physical systems we need to include the analysis of the “action” part. We need to try extending the functional deviation to the process equipment. For many process equipment we know the dangerous failure modes, but we should not reveal them if we can learn from them to improve the protection. This because OT cyber security is not limited to implementing countermeasures but includes considering safeguards. In IT security, there is a focus on the data part for example: the capturing of access credentials; credit card numbers; etc.
In OT security need to understand the action, the relevant failure modes. As explained in prior blogs, these actions are in the two categories I have mentioned several times: Loss of Required Performance (deviating from design or operations intent) and Loss of Ability to Perform (the function is not available). I know that many people like to hang on to the CIA or AIC triad, or want to extend, the key element in OT cyber security are these functional deviations that cause the process failures to address these on both the likelihood and impact factors we need to consider the function and than CIA or AIC is not very useful. The definitions used by the asset integrity discipline offer us far more.
Both loss of required performance and loss of ability to perform are equally important. Causing the failure modes linked to loss of required performance the threat actor can initiate the functional deviation that is required to impact the physical system, with failure modes associated with the loss of ability to perform the threat actor can prevent detection and / or correction of a functional deviation or deviation in the physical state of the production process.
The level of importance is linked to loss and both categories can cause this loss, it is not that Loss of Performance (kind of equivalent of the IT integrity term) or Loss of Ability to Perform (The IT availability term) cause different levels of loss. The level of loss depends on how the attacker uses these failure modes to cause the loss, a loss of ability can easily result in a runaway reaction without the need of manipulation of the process function, some production processes are intrinsically unstable.
All we can say is that loss of confidentiality is in general the least important loss if we consider sabotage, but can of course lead to enabling the other two if it concerns confidential access credentials or design information.
Let’s leave the stage-zero-thinking for a moment and discuss the use of the HAZOP / PHA technique for OT cyber security.
I mentioned it in previous blogs, a cyber attack scenario can be defined as:
A THREAT ACTOR initiates a THREAT ACTION exploiting a VULNERABILITY to achieve a certain CONSEQUENCE.
This we can call an event path, a sequence of actions to achieve a specific objective. A threat actor can chain event paths, for example in the initial event path he can conduct a phishing attack to capture login credentials, followed-up by an event path accessing the ICS and causing an uncontrolled shut down of a blast furnace. The scenario discussed in the blog on the German steel mill attack. I extend this concept in the following picture by adding controls detailing the consequence.
Event path
In order to walk the event path a threat actor has to overcome several hurdles, the protective controls used by the defense team to reduce the risk. There are countermeasures acting on the likelihood side (for instance firewalls, antivirus, application white listing, etc.) and we have safeguards / barriers acting on the consequence side to reduce consequence severity by blocking consequences to happen or detect them in time to respond.
In principal we can evaluate risk for event paths if we assign an initiating event frequency to the threat event, have a method to “measure” risk reduction, and have a value for consequence severity. The method to do this is equivalent to the method used in process safety Layer Of Protection Analysis (LOPA).
In LOPA the risk reduction is among others a factor of the probability of demand (PFD) factor we assign to each safeguard, there are tables that provide the values, the “credit” we take for implementing them. The multiplication of safeguard PFDs in the successive protection layers provides a risk reduction factor (RRF). If multiplied with the initiating event frequency we get the mitigated event frequency (MEF). We can have multiple layers of protection allowing us to reduce the risk. The inverse of the MEF is representative for the likelihood and we can use it for the calculation of residual risk. In OT cyber security the risk estimation method is similar, also here we can benefit from multiple protection layers. But maybe in a future blog more detail on how this is done and how detection comes into the picture to get a consistent and repeatable manner for deriving the likelihood factor.
To prevent questions, I probably already explained in a previous blog, but for risk we have multiple estimation methods. We can use risk to predict an event to happen, this is called temporal risk, we need statistical information to get a likelihood. We might get this one day if we have every day an attack on ICS, but today there is not enough statistical data for ICS cyber attacks to estimate temporal risk. So we need another approach, and this is what is called a risk priority number.
Risk priority numbers allow us to rank risk, we can’t predict but we can show which risk is more important than another and we can indicate which hazard is more likely to occur than another. This is done by creating a formula to estimate the likelihood of the event path to reach its destination, the consequence.
If we have sufficient independent variables to score for likelihood, we get a reliable difference in likelihood between different event paths.
So it is far from the very subjective assignment method of a likelihood factor by a subject matter expert as explained by a NIST risk specialist in a recent presentation organized by the ICSJWG. Such a method would lead to a very subjective result. But enough about estimating risk this is not the topic today, it is about the principles used.
Counterfactual hazard identification and risk analysis is the method we can use for assessing OT cyber security risk in a high level of detail. Based on John Cusimano’s reaction it looks like an unknown approach. Though the method is at least 10+ years in every proper book on risk analysis and in use. So what is it?
I explained the concept of the event path in the diagram, counterfactual risk analysis (CRA) is not much more than building a large repository with as many event paths as we can think of and then processing them in a specific way.
How do we get these event paths? One way is to study the activities of our “colleagues” working in threat_community inc. They potentially learn us in each attack they execute one or more new event paths. Another way to add event paths is by threat modelling, at least than we become proactive. Since cyber security also entered the development processes of ICS in a much more formal manner, many new products today are being threat modeled. We can benefit of those results. And finally we can threat model ourselves at system level, the various protocols (channels) in use, the network equipment, the computer platforms.
Does such a repository cover all threats, absolutely not but if we do this for a while with a large team of subject matter experts in many projects the repository of event paths grows very quickly. Learning curves become very steep in large expert communities.
How does CRA make use of such a repository? I made a simplified diagram to explain.
The Threat Actor (A) that wants to reach a certain consequence / objective (O), has 4 Threat Actions (TA) at his disposal. Based on A’s capabilities he can execute one or more. Maybe a threat actor with IEC 62443 SL 2 capabilities can only execute 1 threat action, while an SL 3 has the capabilities to execute all threat actions. The threat action attempts to exploit a Vulnerability (V), however sometimes the vulnerability is protected with a countermeasure(s) (C). On the event path the threat actor needs to overcome multiple countermeasures if we have defense in depth, and he needs to overcome safeguards. Based on which countermeasures and safeguards are in place event paths are yes or no available to reach the objective, for example a functional deviation / failure mode. We can assign a severity level to these failure modes (HIGH, MEDIUM, etc)
In a risk assessment the countermeasures are always considered perfect, there reliability, effectiveness and detection efficiency is included in their PFD. In a threat risk assessment, where also a vulnerability assessment is executed, it becomes possible to account for countermeasure flaws. The risk reduction factor for a firewall that starts with the rule permit any any will certainly not score high on risk reduction.
I think it is clear that if we have an ICS with many different functions (so different functional deviations / consequences, looking at the detailed functionality), different assets executing these functions, many different protocols with their vulnerabilities, operating systems with their vulnerabilities, and different threat actors with different capabilities, the number of event paths grows quickly.
To process this information a CRA hazard analysis tool is required. A tool that creates a risk model for the functions and their event paths in the target ICS. A tool takes the countermeasures and safeguards implemented in the ICS into account, a tool that accounts for the static and dynamic exposure of vulnerabilities, and a tool that accounts for the severity of the consequences. If we combine this with the risk criteria defining the risk appetite / risk tolerance we can estimate risk and can quickly show which hazards have an acceptable risk, tolerable risk, or unacceptable risk.
So a CRA tool builds the risk model through configuring the site specific factors, for the attacks it relies on the repository of event paths. Based on the site specific factors some event paths are impossible, others might be possible with various degrees of risk. More over such a CRA tool makes it possible to show additional risk reduction by enabling more countermeasures. Various risk groupings become possible, for example it becomes possible to estimate risk for the whole ICS if we take the difference in criticality between the functions into account. We might want to group malware related risk by filtering on threat actions based on malware attacks or other combinations of threat actions.
Such a tool can differentiate risk for each threat actor with a defined set of TTP. So it becomes possible to compare SL 2 threat actor risk with SL 3 threat actor risk. Once we have a CRA model many points of view become available, could even see risk vary for the same configuration if the repository grows.
So there is a choice, either a csHAZOP process with a workshop where the subject matter experts discuss the various threats. Or using a CRA approach where the workshop is used to conduct a criticality assessment, consequence analysis, and determine the risk criteria. It is my opinion that the CRA approach offers more value.
So finally what has this all to do with the title “playing chess on the ICS board”? Well apart from a OT security professional I was also a chess player, playing chess in times there was no computer capable of playing a good game.
The Dutch former world champion Max Euwe (also professor Informatics) was of the opinion that computers can’t play chess at a level to beat the strongest human chess players. He thought human ingenuity can’t be put in a machine, this is about 50 years ago.
However large sums of money were invested in developing game theory and programs to show that computers computers can beat humans. The first time that this happened was when an IBM computer program “Deep Blue” won from then reigning world champion Gary Kasparov in 1997. The computers approached the problem brute force in those days, generating for each position all the possible moves, analyzing the position after the move and going to the next level for a new move for the move or moves that scored best. Computers could do this so efficiently that looked 20/30 moves (plies) ahead, far more than any human could do. Humans had to use their better understanding of the position and its weaknesses and defensive capabilities.
But the deeper a computer could look and the better its assessment of the position became the stronger it became. And twenty years ago it was quite normal that machines could beat humans at chess, including the strongest players. This was the time that chess games could not be adjourned anymore because a computer could analyse the position. Computers were used by all top players to check their analysis in the preparation of games, it considerably changed the way chess was played.
Than recently we had the next generation based on AI (E.g. Alpha Zero) and again the AI machines proofed stronger, stronger then the machines making use of the brute force method. But these AI machines offered more, the additional step was that humans started to learn from the machine. The loss was no longer caused by our brains not being able to analyze so many variations, but the computer actually understood the position better. Based upon all the games played by people the computers recognized patterns that were successful and patterns that would ultimately lead to failure. Plans that were considered very dubious by humans were suddenly shown to be very good. So grandmasters learned and adopted this new knowledge even by today’s world champion Magnus Carlsen.
So contrary John’s claim if we are able to model the problem we create a path where computers can conquer complex problems and ultimately be better than us.
CRA is not brute force – randomly generating threat paths – but processing the combined knowledge of OT security specialists with detailed knowledge of the inner workings of the ICS functions contained in a repository. Kind of the patterns recognized by the AI computer.
CRA is not making chess moves on a chess board, but verifying if an event path to a consequence (Functional deviation / failure mode) is available. An event path is a kind of move, it is a plan to a profitable consequence.
Today CRA uses a repository made and maintained by humans, but I don’t exclude it that tomorrow AI assisting us to consider which threats might work and which not. Maybe science fiction, but I saw it happen with chess, Go, and many other games. Once you model a problem computers have proofed to be great assistants and even proofed to be better than humans. CRA exists today, an AI based CRA may exist tomorrow.
So in my opinion the HAZOP method in the form applied to process safety and in computer HAZOPs leads to a generalization of the threats when applied for cyber security because of the complexity of the analysis. Generalization leads to results comparable with security standard-based or security-compliance-based strategies. For some problems we just don’t need risk, if I cross a street I don’t have to estimate the risk. Crossing in a straight line – shortest path – will reduce the risk. The risk would be mainly how busy the road is.
For achieving the benefits of a risk based approach in OT cyber security we need tooling to process all the hazards (event paths) identified by threat modelling. The more event paths we have in our brain, the repository, the more value the analysis produces. Counter fact risk analysis is the perfect solution for achieving this, it provides a consistent detailed result allowing for looking at risk from many different viewpoints. So computer applications offer significant value, by offering a more in depth analysis, for risk analysis if we apply the right risk methodology.
There is no relationship between my opinions and references to publications in this blog and the views of my employer in whatever capacity. This blog is written based on my personal opinion and knowledge build up over 42 years of work in this industry. Approximately half of the time working in engineering these automation systems, and half of the time implementing their networks and securing them.