
Are there rules an engineer must follow when executing a new project? This week Yacov Haimes passed away at the age of 86 years. Haimes was an American of Iraqi decent and a monument when it comes to risk modeling of what he called systems of systems. His many publications among which his books “Modeling and Managing Interdependent Complex Systems of Systems” (2019) and “Risk Modeling, Assessment, And Management” (2016) provided me with a lot of valuable insights that assisted me to execute and improve quantitative risk assessments in the process industry. He was a man who tried to analyze and formalize the subjects he taught and as such created some “models” that helped me to better understand what I was doing and guide me along the way.
Readers that followed my prior blogs know that I consider automation systems as Systems of Systems (SoS) and have discussed these systems and their interdependencies and interconnectedness (I-I) often in the context of OT security risk. In this blog I like to discuss some of these principles and point to some of the gaps I noticed in methods and standards used for risk assessments conflicting with these principles. To start the topic I introduce a model that is a merger between two methods, on one side the famous 7 habits of Covey and on the other side a system’s development process, and use this model as a reference for the gaps I see. Haimes and Schneiter published this model in a 1996 IEEE publication, I kind of recreated the model in Visio so we can use it as a reference.


I just pick a few points per habit where I see gaps between the present practice advised by standards of risk engineering / assessment and some practical hurdles. But I like to encourage the reader to study the model in far more detail than I cover in this short blog.
The first Stephen Covey habit is, habit number 1 “Be proactive” and points to the engineering steps that assist us in defining the risk domain boundaries and help us to understand the risk domain itself. When we start a risk analysis we need to understand what we call the “System under Consideration”, the steps linked to habit 1 describe this process. Let’s compare this for four different methods and discuss how these methods implement these steps, I show them above each other in the diagram so the results remain readable.


The ISO 31000 is a very generic model, that can be used both for quantitative risk assessment as well as qualitative risk assessment. (See for the definitions of risk assessments my previous blog) The NORSOK model is a quantitative risk model used for showing compliance with quantitative risk criteria for human safety and the environment. The IEC/ISA 62443.3.2 model is a generic or potentially a qualitative risk model specifically constructed for cyber security risk as used by the IEC/ISA 62443 standard in general. The CCPS model is a quantitative model for quantitative process safety analysis. It is the 3rd step in a refinement process starting with HAZOP, then LOPA, and if more detail is required than CPQRA.
Where do these four differ if we look at the first two habits of Covey? The proactive part is covered by all methods, though CCPS indicates a focus on scenarios, this is primarily so because the HAZOP covers the identification part in great detail. Never the less for assessing risk we need scenarios.
An important difference between the models rises from habit 2 “Begin with the end”. When we engineer something we need clear criteria, what is the overall objective and when is the result of our efforts (in the case of a risk assessment and risk reduction, the risk) acceptable?
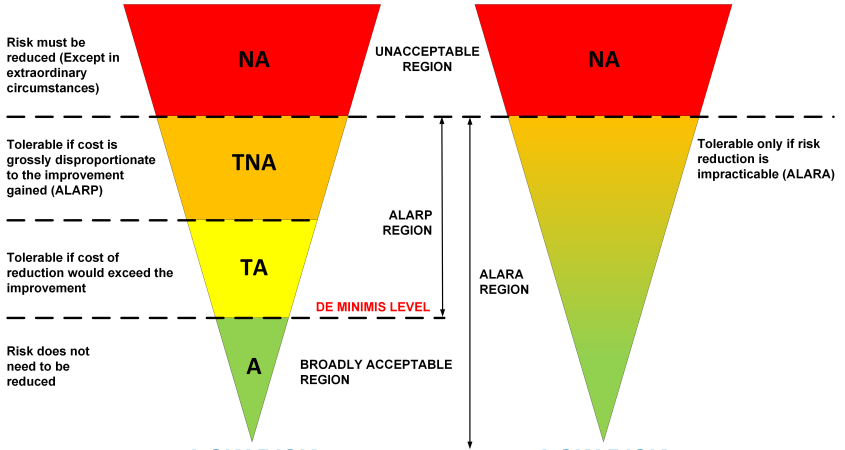
This is the first complexity and strangely enough are these criteria a hot topic between continents, my little question “when is risk acceptable?” is for many Americans an unacceptable question, the issue is their legal system which mixes “acceptability” and “accountability” so they translate this into “when is risk tolerable”. However the problem here is that there are multiple levels for tolerable. European law is as usual diverse, we have countries that follow the ALARP principle (As Low As Reasonably Practical) and we have countries that follow the ALARA principle (As Low As Reasonably Achievable). ALARP has a defined “DE MINIMIS” level, kind of a minimum level where we can say risk is reduced to a level that is considered an acceptable risk reduction by a court of law. Contrary to ALARA where we need to reduce the risk to the level it is no longer practicable, so there is no cost criterium but only a pure technical criterium.

For example the IEC/ISA 62443-3-2 standard compares risk with the tolerable level without defining what that level is. For an ALARA country (e.g. Germany, Netherlands) that level is clearly defined by the law and the IEC / ISA interpretation (stopping further risk reduction at this level) would not be acceptable, for an ALARP country (e.g. UK) the limits and conditions are also well defined but cost related. The risk reduction must go all the way to the DE MINIMUS level if cost would allow it. Which is in cyber security for a chemical plant often the case, this because the cost of a cyber incident – that can cause one or multiple fatalities – in the UK this cost is generally higher than the cost of the cyber security measures that could have prevented it. The cost of a UK fatality is set to approx. 1.5 million pound, actually an American is triple that cost 😊according to the US legal system, the Dutch and Germans (being ALARA) are of course priceless.
So it is important to have clear risk acceptance criteria established and objectives when we start a risk assessment. If we don’t – such as is the case for IEC/ISA 62443.3.2 comparing initial and residual risk with some vaguely defined tolerable risk level – the risk reduction most likely fails a legal test in a court room. ALARP / ALARA are also legal definitions, and cyber security also needs to meet these. Therefore the step risk planning is an essential element of the first NORSOK step and in my opinion should always be the first step, engineering requires a plan towards a goal.
Another very important element according Haines is the I-I (interdependencies, interconnectedness) element. Interconnectedness is covered by IEC/ISA 624433.2 by the zone and conduit diagram, conduits connect zones, though these conduits are not necessarily documented at the level allowing us to identify connections within the zone that can be of relevance for cyber risk (consider e.g. ease of malware propagation within a zone).
Interdependencies are ignored by IEC/ISA 62443. The way to identify these interdependencies is typically conducting a criticality analysis or a Failure Mode and Effect Analysis (FMEA). Interdependencies propagate risk because the consequence of function B might depend on the contribution of function A. A very common interdependency in OT is when we take credit in a safety risk analysis for both a safeguard provided by the SIS (e.g. a SIF) and a safeguard provided by the BPCS (e.g. an alarm), if we need to reduce risk with a factor 10.000, there might be a SIL 3 SIF defined (factor 1000) and the BPCS alarm (factor 10). If a cyber attack can disable one of the two the overall risk reduction fails. Disabling process alarms is relatively easy to do with a bit of ARP poisoning, so from a cyber security point of view we have an important interdependency to consider.
Habit 1 and 2 are very important engineering habits, if we follow the prescriptions taught by Haines we certainly shouldn’t ignore the dependencies when we analyze risk as some methods do today. How about habit 3? This habit is designed to help concentrate efforts toward more important activities, how can I link this to risk assessment?
Especially when we do a quantitative risk assessment vulnerabilities aren’t that important, threats have an event frequency and vulnerabilities are merely the enablers. If we consider risk as a method that wants to look into the future, it is not so important what vulnerability we have today. Vulnerabilities come and go, but the threat is the constant factor. The TTP is as such more important than the vulnerability exploited.
Of course we want to know something about the type of vulnerability, because we need to understand how the vulnerability is exposed in order to model it, but if we yes/no have a log4j vulnerability is not so relevant for the risk. Today’s log4j is tomorrow’s log10k. But it is essential to have an extensive inventory of all the potential threats (TTPs) and how often these TTPs have been used. This information is far more accessible than how often a specific exposed (so exploitable) vulnerability exists. We need to build scenarios and analyze the risk per scenario.
Habit 4 is also of key importance, win-win makes people work together to achieve a common goal. The security consultant’s task might be to find the residual risk for a specific system, but the asset owner typically wants more than a result because risk requires monitoring, risk requires periodic reassessment. The engineering method should support these objectives in order to facilitate the risk management process. Engineering should always consider the various trade-offs there are for the asset owner, budgets are limited.
Habit 5 “Seek first to understand, then to be understood” can be directly linked to the risk communication method and linked to the perspective of the asset owner on risk. So reports shouldn’t be thrown over the wall but discussed and explained, results should be linked to the business. Though this might take considerably more time it is never the less very important.
But not an easy habit to acquire as engineer since we often are kind of nerds with an exclusive focus on “our thing” expecting the world to understand what is clear for us. One of the elements that is very important to share with the asset owner are the various scenarios analyzed. The scenario overview provides a good insight in what threats have been evaluated (typically close to 1000 today, so a sizeable document of bow-ties describing the attack scenarios and their consequences) and the overview allows us to identify gaps between the scenarios assessed and the changing threat landscape.
Habit 6 “Synergize”, is to consider all elements of the risk domain but also their interactions and dependencies. There might be influences from outside the risk domain not considered, never the less these need to be identified another reason why dependencies are very important. Risk propagates in many ways, not necessarily exclusively over a network cable.
Habit 7 “Sharpen the saw”, if there is one discipline where this is important than it is cyber risk. The threat landscape is in continuous movement. New attacks occur, new TTP is developed, and proof of concepts published. Also whenever we model a system, we need to maintain that model, improve it, continuously test it and adjust where needed. Threat analysis / modelling is a continuous process, results need to be challenged, new functions added.
Business managers typically like to develop something and than repeat it as often as possible, however an engineering process is a route where we need to keep an open eye for improvements. Habit 7 warns us against the auto-pilot. Risk analysis without following habit 7 results in a routine that doesn’t deliver appropriate results, one reason why risk analysis is a separate discipline not just following a procedure as it still is for some companies.
There is no relationship between my opinions and references to publications in this blog and the views of my employer in whatever capacity. This blog is written based on my personal opinion and knowledge build up over 43 years of work in this industry. Approximately half of the time working in engineering these automation systems, and half of the time implementing their networks and securing them, and conducting cyber security risk assessments for process installations since 2012.
Author: Sinclair Koelemij
OTcybersecurity web site









